J'espère que j'ai bien compris. Alors je vais répéter.
- Vous avez 1 table avec de nombreuses entrées
- Vous avez cette liste d'Excel où vous recherchez la "colonne de recherche"
- En cas de correspondance, remplacer la valeur entière par "remplacer la colonne"
Si tel est le cas, cela pourrait être la solution :
declare @data table (Column1 nvarchar(50))
insert into @data
(Column1)
values (N'RbC investment for Seniors 65+'),
(N'RBC inv for juniors')
declare @replace table
(
OriginalValue nvarchar(50),
NewValue nvarchar(50),
[priority] int
)
insert into @replace
(OriginalValue, NewValue, [priority])
values (N'rbc inv', N'RBC dominion securities', 2),
(N'rbc dom', N'RBC dominion securities', 2),
(N'RBC', N'RBC Bank', 3)
update @data
set Column1 = coalesce((
select top 1
NewValue
from @replace
where Column1 like '%' + OriginalValue + '%'
order by [priority]
), Column1)
select *
from @data
La table "data" serait celle où vous faites le remplacement.
Il peut y avoir pas mal d'effets secondaires en utilisant cela (par exemple, des caractères génériques comme % dans "search_column", peut-être plusieurs correspondances - en ce moment, une "aléatoire" est alors prise, la performance n'est peut-être pas la meilleure, ...) Mais je suppose que pour une réponse plus précise, j'aurais besoin d'une meilleure question.
Modifier :
Merci à Ralph... J'ai ajouté une priorité à la table "replace" pour pouvoir gérer les correspondances en double.
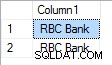
Dans le cas où "RBC" a la priorité 3, le résultat est :
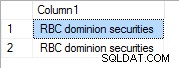
Avec une priorité de 1 c'est :