Les UDF scalaires ont toujours été une épée à double tranchant - elles sont idéales pour les développeurs, qui peuvent s'abstraire de la logique fastidieuse au lieu de la répéter partout dans leurs requêtes, mais elles sont horribles pour les performances d'exécution en production, car l'optimiseur ne le fait pas. t les manipuler bien. Essentiellement, ce qui se passe, c'est que les exécutions UDF sont séparées du reste du plan d'exécution. Elles sont donc appelées une fois pour chaque ligne et ne peuvent pas être optimisées en fonction du nombre estimé ou réel de lignes ou intégrées au reste du plan.
Étant donné que, malgré tous nos efforts depuis SQL Server 2000, nous ne pouvons pas empêcher efficacement l'utilisation des UDF scalaires, ne serait-il pas formidable de faire en sorte que SQL Server les gère simplement mieux ?
SQL Server 2019 introduit une nouvelle fonctionnalité appelée Scalar UDF Inlining. Au lieu de garder la fonction séparée, elle est intégrée dans le plan global. Cela conduit à un bien meilleur plan d'exécution et, par conséquent, à de meilleures performances d'exécution.
Mais d'abord, pour mieux illustrer la source du problème, commençons par une paire de tables simples avec seulement quelques lignes, dans une base de données fonctionnant sur SQL Server 2017 (ou sur 2019 mais avec un niveau de compatibilité inférieur) :
CREATE DATABASE Whatever; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 140; GO USE Whatever; GO CREATE TABLE dbo.Languages ( LanguageID int PRIMARY KEY, Name sysname ); CREATE TABLE dbo.Employees ( EmployeeID int PRIMARY KEY, LanguageID int NOT NULL FOREIGN KEY REFERENCES dbo.Languages(LanguageID) ); INSERT dbo.Languages(LanguageID, Name) VALUES(1033, N'English'), (45555, N'Klingon'); INSERT dbo.Employees(EmployeeID, LanguageID) SELECT [object_id], CASE ABS([object_id]%2) WHEN 1 THEN 1033 ELSE 45555 END FROM sys.all_objects;
Maintenant, nous avons une requête simple où nous voulons montrer chaque employé et le nom de sa langue principale. Disons que cette requête est utilisée dans de nombreux endroits et/ou de différentes manières, donc, au lieu de créer une jointure dans la requête, nous écrivons une UDF scalaire pour faire abstraction de cette jointure :
CREATE FUNCTION dbo.GetLanguage(@id int) RETURNS sysname AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END
Ensuite, notre requête réelle ressemble à ceci :
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Si nous regardons le plan d'exécution de la requête, il manque étrangement quelque chose :
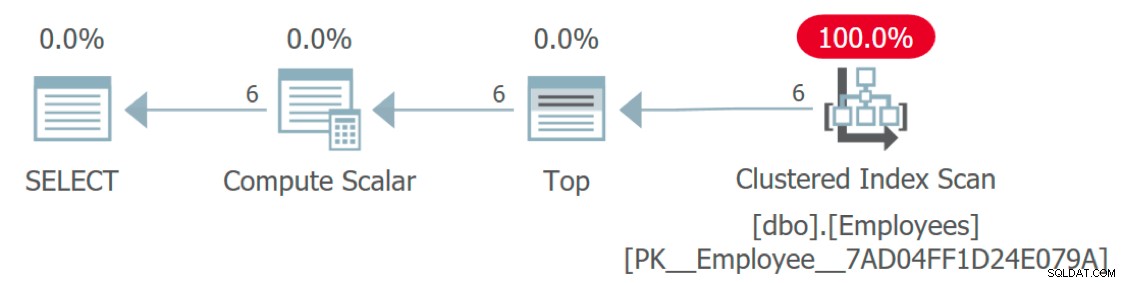 Plan d'exécution indiquant l'accès aux employés mais pas aux langues
Plan d'exécution indiquant l'accès aux employés mais pas aux langues
Comment accède-t-on au tableau Langues ? Ce plan semble très efficace parce que, comme la fonction elle-même, il fait abstraction d'une partie de la complexité impliquée. En fait, ce plan graphique est identique à une requête qui se contente d'affecter une constante ou une variable au Language colonne :
SELECT TOP (6) EmployeeID, Language = N'Sanskrit' FROM dbo.Employees;
Mais si vous exécutez une trace sur la requête d'origine, vous verrez qu'il y a en fait six appels à la fonction (un pour chaque ligne) en plus de la requête principale, mais ces plans ne sont pas renvoyés par SQL Server.
Vous pouvez également vérifier cela en vérifiant sys.dm_exec_function_stats , mais ce n'est pas une garantie :
SELECT [function] = OBJECT_NAME([object_id]), execution_count FROM sys.dm_exec_function_stats WHERE object_name(object_id) IS NOT NULL;
function execution_count ----------- --------------- GetLanguage 6
SentryOne Plan Explorer affichera les déclarations si vous générez un plan réel à partir du produit, mais nous ne pouvons les obtenir qu'à partir de la trace, et il n'y a toujours pas de plans collectés ou affichés pour les appels de fonction individuels :
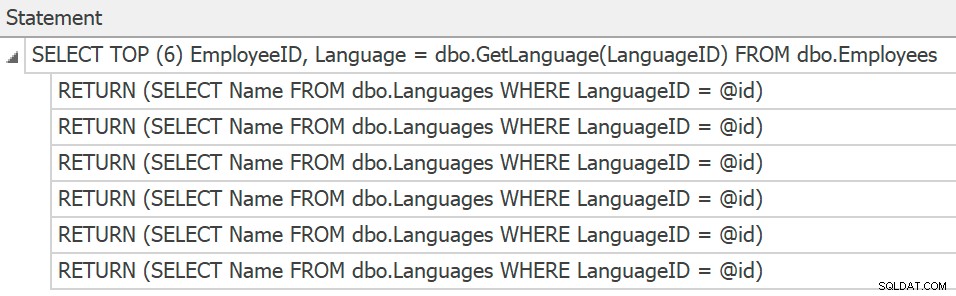 Instructions de trace pour les appels UDF scalaires individuels
Instructions de trace pour les appels UDF scalaires individuels
Tout cela les rend très difficiles à dépanner, car vous devez aller les traquer, même si vous savez déjà qu'ils sont là. Cela peut également créer un véritable gâchis d'analyse des performances si vous comparez deux plans basés sur des éléments tels que les coûts estimés, car non seulement les opérateurs concernés se cachent du diagramme physique, mais les coûts ne sont pas non plus intégrés nulle part dans le plan.
Avance rapide vers SQL Server 2019
Après toutes ces années de comportement problématique et de causes profondes obscures, ils ont fait en sorte que certaines fonctions puissent être optimisées dans le plan d'exécution global. Scalar UDF Inlining rend les objets auxquels ils accèdent visibles pour le dépannage *et* leur permet d'être intégrés dans la stratégie du plan d'exécution. Désormais, les estimations de cardinalité (basées sur les statistiques) permettent des stratégies de jointure qui n'étaient tout simplement pas possibles lorsque la fonction était appelée une fois pour chaque ligne.
Nous pouvons utiliser le même exemple que ci-dessus, soit créer le même ensemble d'objets sur une base de données SQL Server 2019, soit nettoyer le cache du plan et augmenter le niveau de compatibilité à 150 :
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 150; GO
Maintenant, lorsque nous exécutons à nouveau notre requête à six lignes :
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Nous obtenons un plan qui inclut le tableau Langues et les coûts associés à son accès :
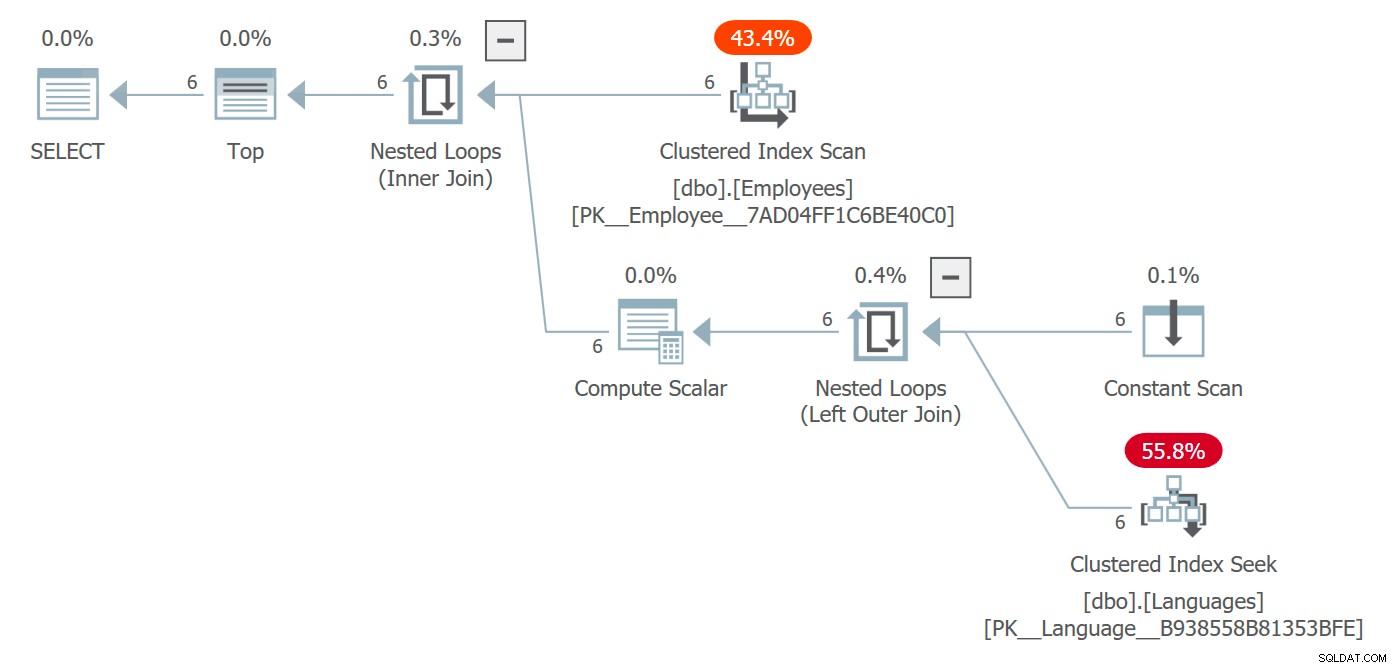 Plan qui inclut l'accès aux objets référencés dans la FDU scalaire
Plan qui inclut l'accès aux objets référencés dans la FDU scalaire
Ici, l'optimiseur a choisi une jointure à boucles imbriquées mais, dans des circonstances différentes, il aurait pu choisir une stratégie de jointure différente, envisager le parallélisme et être essentiellement libre de modifier complètement la forme du plan. Vous ne verrez probablement pas cela dans une requête qui renvoie 6 lignes et ne pose aucun problème de performances, mais à plus grande échelle, cela pourrait être le cas.
Le plan reflète que la fonction n'est pas appelée par ligne - alors que la recherche est en fait exécutée six fois, vous pouvez voir que la fonction elle-même n'apparaît plus dans sys.dm_exec_function_stats . Un inconvénient que vous pouvez retirer est que, si vous utilisez ce DMV pour déterminer si une fonction est activement utilisée (comme nous le faisons souvent pour les procédures et les index), cela ne sera plus fiable.
Mises en garde
Toutes les fonctions scalaires ne sont pas inlineables et, même lorsqu'une fonction *est* inlineable, elle ne sera pas nécessairement inlineable dans tous les scénarios. Cela a souvent à voir avec la complexité de la fonction, la complexité de la requête impliquée ou la combinaison des deux. Vous pouvez vérifier si une fonction est inlineable dans le sys.sql_modules vue catalogue :
SELECT OBJECT_NAME([object_id]), definition, is_inlineable FROM sys.sql_modules;
Et si, pour une raison quelconque, vous ne voulez pas qu'une certaine fonction (ou n'importe quelle fonction dans une base de données) soit intégrée, vous n'avez pas à vous fier au niveau de compatibilité de la base de données pour contrôler ce comportement. Je n'ai jamais aimé ce couplage lâche, qui s'apparente à changer de salle pour regarder une émission de télévision différente au lieu de simplement changer de chaîne. Vous pouvez contrôler cela au niveau du module à l'aide de l'option INLINE :
ALTER FUNCTION dbo.GetLanguage(@id int) RETURNS sysname WITH INLINE = OFF AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END GO
Et vous pouvez contrôler cela au niveau de la base de données, mais indépendamment du niveau de compatibilité :
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF;
Bien que vous deviez avoir un assez bon cas d'utilisation pour balancer ce marteau, à mon humble avis.
Conclusion
Maintenant, je ne suggère pas que vous puissiez extraire chaque élément de logique dans une UDF scalaire et supposer que maintenant SQL Server s'occupera de tous les cas. Si vous avez une base de données avec beaucoup d'utilisation UDF scalaire, vous devez télécharger le dernier CTP SQL Server 2019, y restaurer une sauvegarde de votre base de données et vérifier le DMV pour voir combien de ces fonctions seront inlineables le moment venu. Cela pourrait être un point majeur la prochaine fois que vous plaidez pour une mise à niveau, car vous récupérerez essentiellement toutes ces performances et cette perte de temps de dépannage.
En attendant, si vous souffrez de performances UDF scalaires et que vous n'allez pas mettre à niveau vers SQL Server 2019 de si tôt, il peut y avoir d'autres moyens d'atténuer le ou les problèmes.
Remarque :J'ai écrit et mis en file d'attente cet article avant de réaliser que j'avais déjà posté un article différent ailleurs.