SQL Server 2008 a introduit les colonnes éparses comme méthode pour réduire le stockage des valeurs nulles et fournir des schémas plus extensibles. Le compromis est qu'il y a une surcharge supplémentaire lorsque vous stockez et récupérez des valeurs non NULL. J'étais intéressé à comprendre le coût du stockage des valeurs non NULL, après avoir parlé à un client qui utilisait ce type de données dans un environnement intermédiaire. Ils cherchent à optimiser les performances d'écriture, et je me demandais si l'utilisation de colonnes éparses avait un effet, car leur méthode nécessitait d'insérer une ligne dans la table, puis de la mettre à jour. J'ai créé un exemple artificiel pour cette démo, expliqué ci-dessous, afin de déterminer s'il s'agissait d'une bonne méthodologie à utiliser.
Examen interne
Pour un examen rapide, rappelez-vous que lorsque vous créez une colonne pour une table qui autorise les valeurs NULL, s'il s'agit d'une colonne de longueur fixe (par exemple, un INT), elle consommera toujours toute la largeur de la colonne sur la page même lorsque la colonne est NUL. S'il s'agit d'une colonne de longueur variable (par exemple, VARCHAR), elle consommera au moins deux octets dans le tableau de décalage de colonne lorsque NULL, à moins que les colonnes ne se trouvent après la dernière colonne remplie (voir le blog de Kimberly. L'ordre des colonnes n'a pas d'importance… généralement , mais – CELA DÉPEND). Une colonne clairsemée ne nécessite aucun espace sur la page pour les valeurs NULL, qu'il s'agisse d'une colonne de longueur fixe ou de longueur variable, et quelles que soient les autres colonnes remplies dans la table. Le compromis est que lorsqu'une colonne clairsemée est remplie, elle prend quatre (4) octets de stockage de plus qu'une colonne non clairsemée. Par exemple :
| Type de colonne | Exigence de stockage |
|---|---|
| Colonne BIGINT, non clairsemée, avec non valeur | 8 octets |
| Colonne BIGINT, non clairsemée, avec une valeur | 8 octets |
| Colonne BIGINT, clairsemée, avec non valeur | 0 octet |
| Colonne BIGINT, clairsemée, avec une valeur | 12 octets |
Par conséquent, il est essentiel de confirmer que l'avantage du stockage l'emporte sur l'impact potentiel de la récupération sur les performances - qui peut être négligeable en fonction de l'équilibre des lectures et des écritures par rapport aux données. Les économies d'espace estimées pour différents types de données sont documentées dans le lien Livres en ligne fourni ci-dessus.
Scénarios de test
J'ai configuré quatre scénarios différents pour les tests, décrits ci-dessous, et chaque table avait une colonne ID (INT), une colonne Nom (VARCHAR(100)) et une colonne Type (INT), puis 997 colonnes NULLABLE.
| ID de test | Description du tableau | Opérations DML |
|---|---|---|
| 1 | 997 colonnes de type de données INT, NULLABLE, non fragmentées | Insérez une ligne à la fois, en remplissant ID, Nom, Type et dix (10) colonnes NULLABLE aléatoires |
| 2 | 997 colonnes de type de données INT, NULLABLE, clairsemées | Insérez une ligne à la fois, en remplissant ID, Nom, Type et dix (10) colonnes NULLABLE aléatoires |
| 3 | 997 colonnes de type de données INT, NULLABLE, non fragmentées | Insérez une ligne à la fois, en remplissant ID, Nom, Type uniquement, puis mettez à jour la ligne, en ajoutant des valeurs pour dix (10) colonnes NULLABLE aléatoires |
| 4 | 997 colonnes de type de données INT, NULLABLE, clairsemées | Insérez une ligne à la fois, en remplissant ID, Nom, Type uniquement, puis mettez à jour la ligne, en ajoutant des valeurs pour dix (10) colonnes NULLABLE aléatoires |
| 5 | 997 colonnes de type de données VARCHAR, NULLABLE, non fragmentées | Insérez une ligne à la fois, en remplissant ID, Nom, Type et dix (10) colonnes NULLABLE aléatoires |
| 6 | 997 colonnes de type de données VARCHAR, NULLABLE, clairsemées | Insérez une ligne à la fois, en remplissant ID, Nom, Type et dix (10) colonnes NULLABLE aléatoires |
| 7 | 997 colonnes de type de données VARCHAR, NULLABLE, non fragmentées | Insérez une ligne à la fois, en remplissant ID, Nom, Type uniquement, puis mettez à jour la ligne, en ajoutant des valeurs pour dix (10) colonnes NULLABLE aléatoires |
| 8 | 997 colonnes de type de données VARCHAR, NULLABLE, clairsemées | Insérez une ligne à la fois, en remplissant ID, Nom, Type uniquement, puis mettez à jour la ligne, en ajoutant des valeurs pour dix (10) colonnes NULLABLE aléatoires |
Chaque test a été exécuté deux fois avec un ensemble de données de 10 millions de lignes. Les scripts joints peuvent être utilisés pour répliquer les tests, et les étapes étaient les suivantes pour chaque test :
- Créer une nouvelle base de données avec des données pré-dimensionnées et des fichiers journaux
- Créez le tableau approprié
- Statistiques d'attente d'instantanés et statistiques de fichiers
- Notez l'heure de début
- Exécuter le DML (une insertion ou une insertion et une mise à jour) pour 10 millions de lignes
- Notez l'heure d'arrêt
- Créer des statistiques d'attente et des statistiques de fichiers et écrire dans une table de journalisation dans une base de données distincte sur un stockage séparé
- Instantané dm_db_index_physical_stats
- Supprimer la base de données
Les tests ont été effectués sur un Dell PowerEdge R720 avec 64 Go de mémoire et 12 Go alloués à l'instance SQL Server 2014 SP1 CU4. Des SSD Fusion-IO ont été utilisés pour le stockage des données des fichiers de base de données.
Résultats
Les résultats des tests sont présentés ci-dessous pour chaque scénario de test.
Durée
Dans tous les cas, il fallait moins de temps (11,6 minutes en moyenne) pour remplir le tableau lorsque des colonnes éparses étaient utilisées, même lorsque la ligne était insérée pour la première fois, puis mise à jour. Lorsque la ligne a été insérée pour la première fois, puis mise à jour, le test a pris presque deux fois plus de temps à s'exécuter par rapport au moment où la ligne a été insérée, car deux fois plus de modifications de données ont été exécutées.
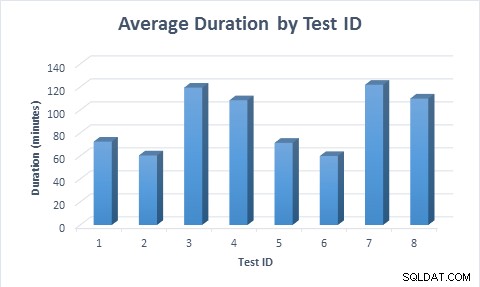 Durée moyenne pour chaque scénario de test
Durée moyenne pour chaque scénario de test
Statistiques d'attente
| ID de test | Pourcentage moyen | Attente moyenne (secondes) |
|---|---|---|
| 1 | 16.47 | 0.0001 |
| 2 | 14.00 | 0.0001 |
| 3 | 16.65 | 0.0001 |
| 4 | 15.07 | 0.0001 |
| 5 | 12.80 | 0.0001 |
| 6 | 13,99 | 0.0001 |
| 7 | 14,85 | 0.0001 |
| 8 | 15.02 | 0.0001 |
Les statistiques d'attente étaient cohérentes pour tous les tests et aucune conclusion ne peut être tirée sur la base de ces données. Le matériel a suffisamment répondu aux demandes de ressources dans tous les cas de test.
Statistiques du fichier
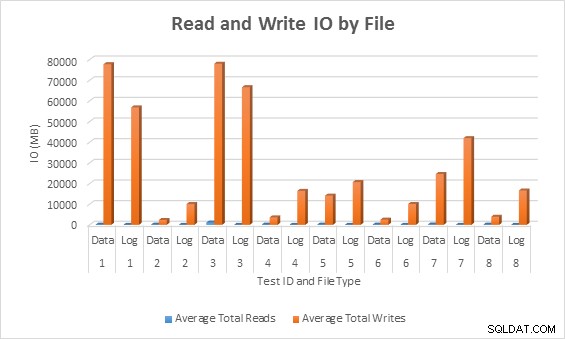 E/S moyennes (lecture et écriture) par fichier de base de données
E/S moyennes (lecture et écriture) par fichier de base de données
Dans tous les cas, les tests avec des colonnes sparses ont généré moins d'E/S (notamment des écritures) par rapport aux colonnes non sparses.
Indexer les statistiques physiques
| Cas de test | Nombre de lignes | Nombre total de pages (index clusterisé) | Espace total (Go) | Espace moyen utilisé pour les pages feuille dans CI (%) | Taille moyenne des enregistrements (octets) |
|---|---|---|---|---|---|
| 1 | 10 000 000 | 10 037 312 | 76 | 51.70 | 4 184,49 |
| 2 | 10 000 000 | 301 429 | 2 | 98.51 | 237,50 |
| 3 | 10 000 000 | 10 037 312 | 76 | 51.70 | 4 184,50 |
| 4 | 10 000 000 | 460 960 | 3 | 64.41 | 237,50 |
| 5 | 10 000 000 | 1 823 083 | 13 | 90.31 | 1 326,08 |
| 6 | 10 000 000 | 324 162 | 2 | 98.40 | 255.28 |
| 7 | 10 000 000 | 3 161 224 | 24 | 52.09 | 1 326,39 |
| 8 | 10 000 000 | 503 592 | 3 | 63.33 | 255.28 |
Des différences significatives existent dans l'utilisation de l'espace entre les tables non clairsemées et clairsemées. Ceci est particulièrement notable lorsque l'on examine les cas de test 1 et 3, où un type de données de longueur fixe a été utilisé (INT), par rapport aux cas de test 5 et 7, où un type de données de longueur variable a été utilisé (VARCHAR(255)). Les colonnes d'entiers consomment de l'espace disque même lorsqu'elles sont NULL. Les colonnes de longueur variable consomment moins d'espace disque, car seuls deux octets sont utilisés dans le tableau de décalage pour les colonnes NULL, et aucun octet pour les colonnes NULL qui se trouvent après la dernière colonne remplie de la ligne.
De plus, le processus d'insertion d'une ligne puis de mise à jour provoque une fragmentation pour le test de colonne de longueur variable (cas 7), par rapport à la simple insertion de la ligne (cas 5). La taille du tableau double presque lorsque l'insertion est suivie de la mise à jour, en raison des fractionnements de page qui se produisent lors de la mise à jour des lignes, ce qui laisse les pages à moitié pleines (contre 90 % pleines).
Résumé
En conclusion, nous constatons une réduction significative de l'espace disque et des E/S lorsque des colonnes éparses sont utilisées, et elles fonctionnent légèrement mieux que les colonnes non éparses dans nos tests de modification de données simples (notez que les performances de récupération doivent également être prises en compte ; peut-être le sujet d'un autre message).
Les colonnes éparses ont un scénario d'utilisation très spécifique et il est important d'examiner la quantité d'espace disque économisée, en fonction du type de données de la colonne et du nombre de colonnes qui seront généralement remplies dans la table. Dans notre exemple, nous avions 997 colonnes éparses et nous n'en avons rempli que 10. Au plus, dans le cas où le type de données utilisé était entier, une ligne au niveau feuille de l'index clusterisé consommerait 188 octets (4 octets pour l'ID, 100 octets max pour le Nom, 4 octets pour le type, puis 80 octets pour 10 colonnes). Lorsque 997 colonnes n'étaient pas clairsemées, 4 octets étaient alloués à chaque colonne, même si NULL, de sorte que chaque ligne comportait au moins 4 000 octets au niveau feuille. Dans notre scénario, les colonnes clairsemées sont tout à fait acceptables. Mais si nous remplissons 500 colonnes éparses ou plus avec des valeurs pour une colonne INT, le gain d'espace est perdu et les performances de modification peuvent ne plus être meilleures.
En fonction du type de données de vos colonnes et du nombre prévu de colonnes à remplir sur le total, vous souhaiterez peut-être effectuer des tests similaires pour vous assurer que, lors de l'utilisation de colonnes éparses, les performances d'insertion et le stockage sont comparables ou meilleurs que lors de l'utilisation de non -colonnes clairsemées. Dans les cas où toutes les colonnes ne sont pas remplies, les colonnes éparses valent vraiment la peine d'être envisagées.



