La concaténation groupée est un problème courant dans SQL Server, sans fonctionnalités directes et intentionnelles pour le prendre en charge (comme XMLAGG dans Oracle, STRING_AGG ou ARRAY_TO_STRING(ARRAY_AGG()) dans PostgreSQL et GROUP_CONCAT dans MySQL). Il a été demandé, mais sans succès pour le moment, comme en témoignent ces éléments Connect :
- Connect #247118 :SQL a besoin de la version de la fonction MySQL group_Concat (reporté)
- Connect #728969 :Fonctions d'ensemble ordonné – Clause WITHIN GROUP (Fermée car ne sera pas corrigée)
** MISE À JOUR janvier 2017 ** :STRING_AGG() sera dans SQL Server 2017 ; lire à ce sujet ici, ici et ici.
Qu'est-ce que la concaténation groupée ?
Pour les non-initiés, la concaténation groupée est lorsque vous souhaitez prendre plusieurs lignes de données et les compresser en une seule chaîne (généralement avec des délimiteurs comme des virgules, des tabulations ou des espaces). Certains pourraient appeler cela une "jointure horizontale". Un exemple visuel rapide montrant comment nous compresserions une liste d'animaux appartenant à chaque membre de la famille, de la source normalisée à la sortie "aplatie" :
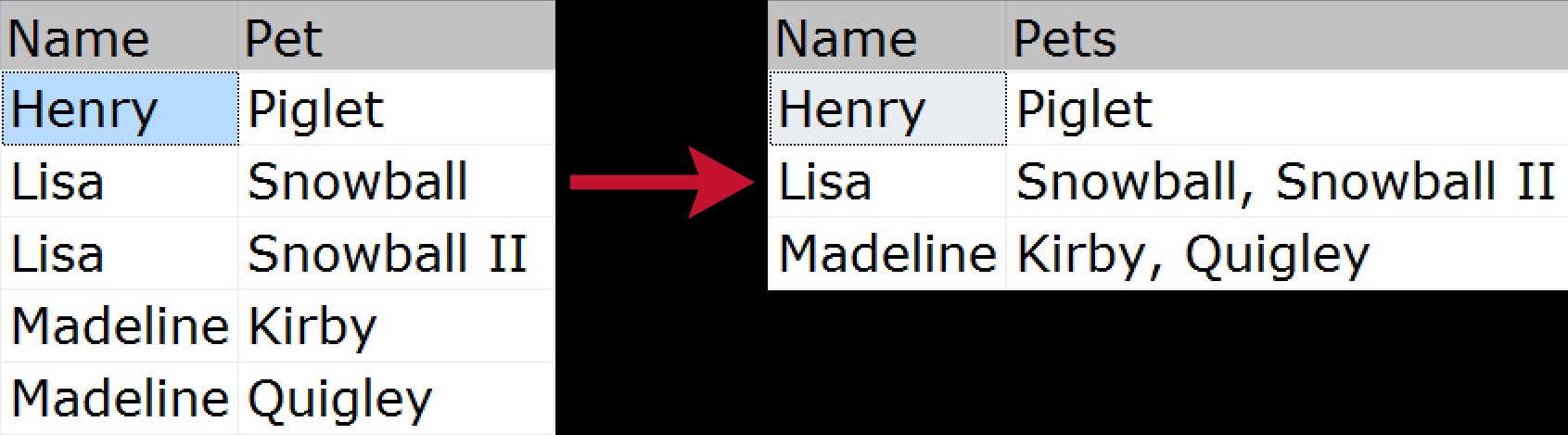
Il y a eu de nombreuses façons de résoudre ce problème au fil des ans; en voici quelques-unes, basées sur les exemples de données suivants :
CREATE TABLE dbo.FamilyMemberPets ( Name SYSNAME, Pet SYSNAME, PRIMARY KEY(Name,Pet) ); INSERT dbo.FamilyMemberPets(Name,Pet) VALUES (N'Madeline',N'Kirby'), (N'Madeline',N'Quigley'), (N'Henry', N'Piglet'), (N'Lisa', N'Snowball'), (N'Lisa', N'Snowball II');
Je ne vais pas présenter une liste exhaustive de toutes les approches de concaténation groupées jamais conçues, car je souhaite me concentrer sur quelques aspects de l'approche que je recommande, mais je souhaite en souligner quelques-unes parmi les plus courantes :
FDU scalaire
CREATE FUNCTION dbo.ConcatFunction
(
@Name SYSNAME
)
RETURNS NVARCHAR(MAX)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @s NVARCHAR(MAX);
SELECT @s = COALESCE(@s + N', ', N'') + Pet
FROM dbo.FamilyMemberPets
WHERE Name = @Name
ORDER BY Pet;
RETURN (@s);
END
GO
SELECT Name, Pets = dbo.ConcatFunction(Name)
FROM dbo.FamilyMemberPets
GROUP BY Name
ORDER BY Name; Remarque :il y a une raison pour laquelle nous ne le faisons pas :
SELECT DISTINCT Name, Pets = dbo.ConcatFunction(Name) FROM dbo.FamilyMemberPets ORDER BY Name;
Avec DISTINCT , la fonction est exécutée pour chaque ligne, puis les doublons sont supprimés ; avec GROUP BY , les doublons sont supprimés en premier.
Exécution du langage commun (CLR)
Cela utilise le GROUP_CONCAT_S fonction trouvée sur https://groupconcat.codeplex.com/ :
SELECT Name, Pets = dbo.GROUP_CONCAT_S(Pet, 1) FROM dbo.FamilyMemberPets GROUP BY Name ORDER BY Name;
CTE récursif
Il existe plusieurs variantes de cette récursivité; celui-ci extrait un ensemble de noms distincts comme ancre :
;WITH x as
(
SELECT Name, Pet = CONVERT(NVARCHAR(MAX), Pet),
r1 = ROW_NUMBER() OVER (PARTITION BY Name ORDER BY Pet)
FROM dbo.FamilyMemberPets
),
a AS
(
SELECT Name, Pet, r1 FROM x WHERE r1 = 1
),
r AS
(
SELECT Name, Pet, r1 FROM a WHERE r1 = 1
UNION ALL
SELECT x.Name, r.Pet + N', ' + x.Pet, x.r1
FROM x INNER JOIN r
ON r.Name = x.Name
AND x.r1 = r.r1 + 1
)
SELECT Name, Pets = MAX(Pet)
FROM r
GROUP BY Name
ORDER BY Name
OPTION (MAXRECURSION 0); Curseur
Pas grand chose à dire ici; les curseurs ne sont généralement pas l'approche optimale, mais cela peut être votre seul choix si vous êtes bloqué sur SQL Server 2000 :
DECLARE @t TABLE(Name SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name));
INSERT @t(Name, Pets)
SELECT Name, N''
FROM dbo.FamilyMemberPets GROUP BY Name;
DECLARE @name SYSNAME, @pet SYSNAME, @pets NVARCHAR(MAX);
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR SELECT Name, Pet
FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
OPEN c;
FETCH c INTO @name, @pet;
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE @t SET Pets += N', ' + @pet
WHERE Name = @name;
FETCH c INTO @name, @pet;
END
CLOSE c; DEALLOCATE c;
SELECT Name, Pets = STUFF(Pets, 1, 1, N'')
FROM @t
ORDER BY Name;
GO Mise à jour originale
Certaines personnes *adorent* cette approche ; Je ne comprends pas du tout l'attraction.
DECLARE @Name SYSNAME, @Pets NVARCHAR(MAX);
DECLARE @t TABLE(Name SYSNAME, Pet SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name, Pet));
INSERT @t(Name, Pet)
SELECT Name, Pet FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
UPDATE @t SET @Pets = Pets = COALESCE(
CASE COALESCE(@Name, N'')
WHEN Name THEN @Pets + N', ' + Pet
ELSE Pet END, N''),
@Name = Name;
SELECT Name, Pets = MAX(Pets)
FROM @t
GROUP BY Name
ORDER BY Name; POUR CHEMIN XML
Assez facilement ma méthode préférée, du moins en partie parce que c'est le seul moyen de * garantir * la commande sans utiliser de curseur ou de CLR. Cela dit, il s'agit d'une version très brute qui ne parvient pas à résoudre quelques autres problèmes inhérents dont je parlerai plus loin :
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N'')), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
J'ai vu beaucoup de gens supposer à tort que le nouveau CONCAT() La fonction introduite dans SQL Server 2012 était la réponse à ces demandes de fonctionnalités. Cette fonction est uniquement destinée à fonctionner sur des colonnes ou des variables d'une seule ligne ; il ne peut pas être utilisé pour concaténer des valeurs sur plusieurs lignes.
En savoir plus sur FOR XML PATH
FOR XML PATH('') en soi n'est pas assez bon - il a connu des problèmes avec l'entitisation XML. Par exemple, si vous mettez à jour l'un des noms d'animaux de compagnie pour inclure une parenthèse HTML ou une esperluette :
UPDATE dbo.FamilyMemberPets SET Pet = N'Qui>gle&y' WHERE Pet = N'Quigley';
Celles-ci sont traduites en entités XML sécurisées quelque part en cours de route :
Qui>gle&y
Donc j'utilise toujours PATH, TYPE).value() , comme suit :
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
J'utilise aussi toujours NVARCHAR , car vous ne savez jamais quand une colonne sous-jacente contiendra Unicode (ou sera modifiée ultérieurement pour le faire).
Vous pouvez voir les variétés suivantes dans .value() , ou même d'autres :
... TYPE).value(N'.', ... ... TYPE).value(N'(./text())[1]', ...
Ceux-ci sont interchangeables, représentant tous finalement la même chaîne; les différences de performances entre eux (voir ci-dessous) étaient négligeables et peut-être complètement non déterministes.
Un autre problème que vous pouvez rencontrer concerne certains caractères ASCII qu'il est impossible de représenter en XML; par exemple, si la chaîne contient le caractère 0x001A (CHAR(26) ), vous obtiendrez ce message d'erreur :
FOR XML n'a pas pu sérialiser les données pour le nœud 'NoName' car il contient un caractère (0x001A) qui n'est pas autorisé dans XML. Pour récupérer ces données à l'aide de FOR XML, convertissez-les en données de type binaire, varbinary ou image et utilisez la directive BINARY BASE64.
Cela me semble assez compliqué, mais j'espère que vous n'avez pas à vous en soucier car vous ne stockez pas de données comme celle-ci ou du moins vous n'essayez pas de les utiliser dans une concaténation groupée. Si tel est le cas, vous devrez peut-être recourir à l'une des autres approches.
Performances
Les exemples de données ci-dessus permettent de prouver facilement que ces méthodes font toutes ce que nous attendons, mais il est difficile de les comparer de manière significative. J'ai donc rempli le tableau avec un ensemble beaucoup plus grand :
TRUNCATE TABLE dbo.FamilyMemberPets; INSERT dbo.FamilyMemberPets(Name,Pet) SELECT o.name, c.name FROM sys.all_objects AS o INNER JOIN sys.all_columns AS c ON o.[object_id] = c.[object_id] ORDER BY o.name, c.name;
Pour moi, il s'agissait de 575 objets, avec 7 080 lignes au total; l'objet le plus large avait 142 colonnes. Là encore, certes, je n'ai pas cherché à comparer toutes les approches conçues dans l'histoire de SQL Server ; juste les quelques faits saillants que j'ai postés ci-dessus. Voici les résultats :
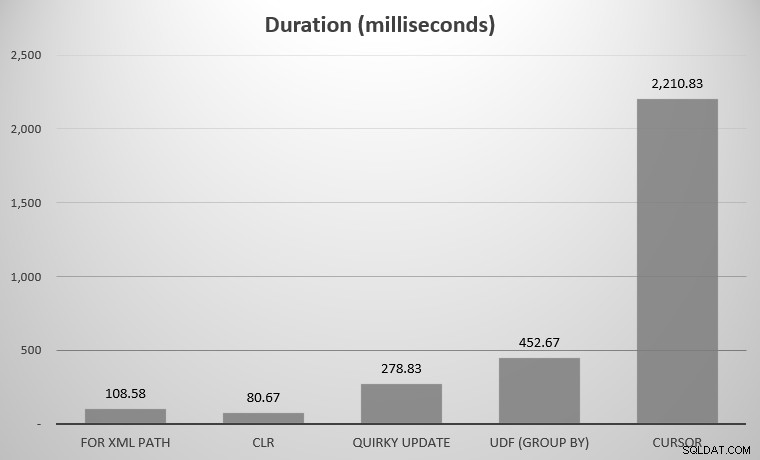
Vous remarquerez peut-être que quelques prétendants manquent à l'appel; la FDU en utilisant DISTINCT et les CTE récursifs étaient tellement hors des tableaux qu'ils fausseraient l'échelle. Voici les résultats des sept approches sous forme de tableau :
| Approche | Durée (millisecondes) |
|---|---|
| POUR CHEMIN XML | 108.58 |
| CLR | 80.67 |
| Mise à jour originale | 278.83 |
| FDU (GROUPER PAR) | 452.67 |
| UDF (DISTINCT) | 5 893,67 |
| Curseur | 2 210,83 |
| CTE récursif | 70 240,58 |
Durée moyenne, en millisecondes, pour toutes les approches
Notez également que les variantes de FOR XML PATH ont été testés indépendamment mais ont montré des différences très mineures, je les ai donc simplement combinés pour la moyenne. Si vous voulez vraiment savoir, le .[1] la notation a fonctionné le plus rapidement dans mes tests; YMMV.
Conclusion
Si vous n'êtes pas dans un magasin où CLR est un obstacle de quelque manière que ce soit, et surtout si vous ne traitez pas uniquement avec des noms simples ou d'autres chaînes, vous devriez certainement envisager le projet CodePlex. N'essayez pas de réinventer la roue, n'essayez pas d'astuces et de hacks non intuitifs pour faire CROSS APPLY ou d'autres constructions fonctionnent juste un peu plus vite que les approches non-CLR ci-dessus. Prenez simplement ce qui fonctionne et branchez-le. Et diable, puisque vous obtenez également le code source, vous pouvez l'améliorer ou l'étendre si vous le souhaitez.
Si CLR est un problème, alors FOR XML PATH est probablement votre meilleure option, mais vous devrez toujours faire attention aux personnages délicats. Si vous êtes bloqué sur SQL Server 2000, votre seule option possible est l'UDF (ou un code similaire non encapsulé dans une UDF).
La prochaine fois
Quelques éléments que je souhaite explorer dans un article de suivi :supprimer les doublons de la liste, classer la liste par autre chose que la valeur elle-même, les cas où mettre l'une de ces approches dans une UDF peut être pénible, et des cas d'utilisation pratiques pour cette fonctionnalité.