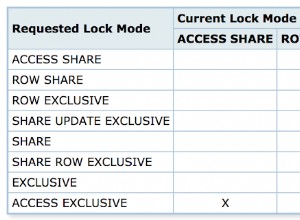
Comme l'écrit Paul :Non, ce n'est pas sûr , pour laquelle je voudrais ajouter des preuves empiriques :Créer une table Table_1 avec un champ ID et un enregistrement avec la valeur 0 . Exécutez ensuite le code suivant simultanément dans deux fenêtres de requête de Management Studio :
declare @counter int
set @counter = 0
while @counter < 1000
begin
set @counter = @counter + 1
INSERT INTO Table_1
SELECT MAX(ID) + 1 FROM Table_1
end
Puis exécutez
SELECT ID, COUNT(*) FROM Table_1 GROUP BY ID HAVING COUNT(*) > 1
Sur mon SQL Server 2008, un ID (662 ) a été créé deux fois. Ainsi, le niveau d'isolement par défaut appliqué aux instructions uniques est not suffisant.
EDIT :clairement, enveloppant le INSERT avec BEGIN TRANSACTION et COMMIT ne le résoudra pas, car le niveau d'isolement par défaut pour les transactions est toujours READ COMMITTED , ce qui n'est pas suffisant. Notez que définir le niveau d'isolement de la transaction sur REPEATABLE READ est aussi insuffisant. La seule façon de rendre le code ci-dessus sûr est d'ajouter
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
au sommet. Cependant, cela provoquait des blocages de temps en temps lors de mes tests.
EDIT :La seule solution que j'ai trouvée qui est sûre et ne produit pas de blocages (du moins dans mes tests) est de verrouiller explicitement la table exclusivement (le niveau d'isolement de la transaction par défaut est suffisant ici). Méfiez-vous cependant; cette solution pourrait tuer performances :
...loop stuff...
BEGIN TRANSACTION
SELECT * FROM Table_1 WITH (TABLOCKX, HOLDLOCK) WHERE 1=0
INSERT INTO Table_1
SELECT MAX(ID) + 1 FROM Table_1
COMMIT
...loop end...