Introduction aux index SQL Server
Microsoft SQL Server est considéré comme l'un des systèmes de gestion de bases de données relationnelles (RDBMS ), dans lequel les données sont logiquement organisées en lignes et en colonnes qui sont stockées dans des conteneurs de données appelés tables. Physiquement, les tableaux sont stockés sous forme de pages de 8 Ko qui peuvent être organisés en tables Heap ou B-Tree Clustered. Dans le tas table, il n'y a pas d'ordre de tri qui contrôle l'ordre des données dans les pages de données et la séquence des pages dans cette table, car il n'y a pas d'index cluster défini sur cette table pour appliquer le mécanisme de tri. Si un index clusterisé est défini sur une colonne du groupe de colonnes de table, les données seront triées à l'intérieur des pages de données en fonction des valeurs des colonnes de clé d'index clusterisé, et les pages seront liées entre elles en fonction de ces valeurs de clé d'index. Ce tableau trié est appelé un tableau clusterisé .
Dans SQL Server, l'index est considéré comme une clé importante et efficace dans le processus de réglage des performances. Le but de la création d'un index est d'accélérer l'accès à la table de base et de récupérer les données demandées sans avoir à parcourir toutes les lignes de la table pour renvoyer les données demandées. Vous pouvez considérer l'index de la base de données comme un index de livre qui vous aide à trouver rapidement les mots dans le livre, sans avoir à lire tout le livre pour trouver ce mot. Par exemple, supposons que vous ayez besoin de récupérer des informations sur un client spécifique à l'aide d'un ID client. Si aucun index n'est défini pour la colonne ID client dans cette table, le moteur SQL Server vérifie toutes les lignes de la table, une par une, afin de récupérer le client avec l'ID fourni. Si un index est défini pour la colonne ID client dans cette table, le moteur SQL Server recherchera les valeurs d'ID client demandées dans l'index trié, plutôt que dans la table de base, pour extraire des informations sur le client, réduisant ainsi le nombre d'analyses. lignes pour récupérer les données.
Dans SQL Server, l'index est structuré logiquement en pages 8K, ou nœuds d'index, sous la forme d'un arbre B. La structure B-Tree contient trois niveaux :un niveau racine qui comprend une page d'index en haut de l'arbre B, un niveau feuille qui se trouve au bas de l'arborescence B et contient des pages de données, et un niveau intermédiaire qui inclut tous les nœuds situés entre les niveaux racine et feuille, avec des valeurs de clé d'index et des pointeurs vers les pages suivantes. Cette forme d'arbre B permet de parcourir rapidement les pages de données de gauche à droite et de haut en bas, en fonction de la clé d'index.
Dans SQL Server, il existe deux principaux types d'index, un index clusterisé dans lequel les données réelles sont stockées au niveau feuille des pages de l'index, avec la possibilité de créer un seul index clusterisé pour chaque table, car les données à l'intérieur des pages de données et l'ordre des pages seront triés en fonction de l'index clusterisé clé. Si vous définissez une contrainte de clé primaire dans votre table, un index clusterisé sera créé automatiquement si aucun index clusterisé n'a été précédemment défini pour cette table. Le deuxième type d'index est un index non clusterisé qui inclut une copie triée des colonnes de clé d'index et un pointeur vers le reste des colonnes de la table de base ou de l'index clusterisé, avec la possibilité de créer jusqu'à 999 index non clusterisés pour chaque table.
SQL Server nous fournit d'autres types d'index spéciaux, tels qu'un index unique qui est créé automatiquement lorsqu'une contrainte d'unicité est définie pour appliquer l'unicité de valeurs de colonne spécifiques, un index composite dans lequel plus d'une colonne clé participera à la clé d'index, un index de couverture dans lequel toutes les colonnes demandées par une requête spécifique participeront à la clé d'index, un index filtré c'est-à-dire un index optimisé non clusterisé avec un prédicat de filtre pour indexer uniquement une petite partie des lignes de la table, un index spatial qui est créé sur les colonnes qui stockent des données spatiales, un index XML qui est créé sur des grands objets binaires XML (BLOB) dans des colonnes de type de données XML, un index Columnstore dans lequel les données sont organisées au format de données en colonnes, un index de texte intégral créé par le moteur de texte intégral SQL Server et un index de hachage qui est utilisé dans les tables optimisées en mémoire.
Comme j'avais l'habitude d'appeler l'index SQL Server, il s'agit d'une épée à double tranchant , où l'optimiseur de requête SQL Server peut bénéficier de l'index bien conçu pour améliorer les performances de vos applications en accélérant le processus de récupération des données. En revanche, un index mal conçu ne sera pas choisi par l'optimiseur de requête SQL Server et dégradera les performances de vos applications en ralentissant les opérations de modification des données et consommera votre stockage sans en tirer parti dans les données. processus de récupération. Par conséquent, il est préférable de suivre d'abord les meilleures pratiques et directives de création d'index, de vérifier l'effet de la création d'un sur l'environnement de développement et de trouver un compromis entre la vitesse des opérations de récupération des données et la surcharge liée à l'ajout de cet index sur les opérations de modification des données. et les besoins en espace de cet index, avant de l'appliquer à l'environnement de production.
Avant de créer un index, vous devez étudier les différents aspects qui affectent la création et l'utilisation de l'index. Cela inclut le type de la charge de travail de la base de données, le traitement des transactions en ligne (OLTP) ou le traitement analytique en ligne (OLAP), la taille de la table , les caractéristiques des colonnes du tableau , l'ordre de tri des colonnes de la requête, le type de l'index qui correspond à la requête et aux propriétés de stockage telles que le FILLFACTOR et PAD_INDEX options qui contrôlent le pourcentage d'espace sur chaque niveau feuille et les pages de niveau intermédiaire à remplir avec des données.
Fragmentation de l'index SQL Server
Votre travail en tant que DBA ne se limite pas à créer le bon index. Une fois l'index créé, vous devez surveiller l'utilisation et les statistiques de l'index, par exemple, vous devez savoir si cet index est mal utilisé ou pas utilisé du tout. Ainsi, vous pouvez fournir la bonne solution pour maintenir ces index ou les remplacer par des index plus efficaces. De cette manière, vous conserverez les performances applicables les plus élevées pour votre système. Vous pouvez vous demander :pourquoi l'optimiseur de requête SQL Server n'utilise-t-il plus mon index, alors qu'il le faisait auparavant ?
La réponse est principalement liée aux changements continus de données et de schéma qui sont effectués sur la table de base et qui doivent être reflétés dans les index. Au fil du temps, et avec tous ces changements, les pages d'index ne sont plus triées, ce qui entraîne la fragmentation de l'index. Une autre raison de la fragmentation est une tentative d'insertion d'une nouvelle valeur ou de mise à jour de la valeur actuelle, et la nouvelle valeur ne rentre pas dans l'espace libre actuellement disponible. Dans ce cas, la page sera divisée en deux pages, où la nouvelle page sera créée physiquement après la dernière page. Et vous pouvez imaginer la lecture d'un index fragmenté et le nombre de pages qui doivent être scannées, et, bien sûr, le nombre d'opérations d'E/S effectuées pour récupérer plusieurs enregistrements en raison de la distance entre ces pages. Et en raison de ce coût supplémentaire lié à l'utilisation de cet index fragmenté, l'optimiseur de requête SQL Server ignorera cet index.
Différentes façons d'obtenir une fragmentation d'index
SQL Server nous propose différentes manières d'obtenir le pourcentage de fragmentation d'index. La première consiste à vérifier le pourcentage de fragmentation de l'index dans l'Index Propriétés fenêtre, sous la rubrique Fragmentation onglet, comme indiqué ci-dessous :
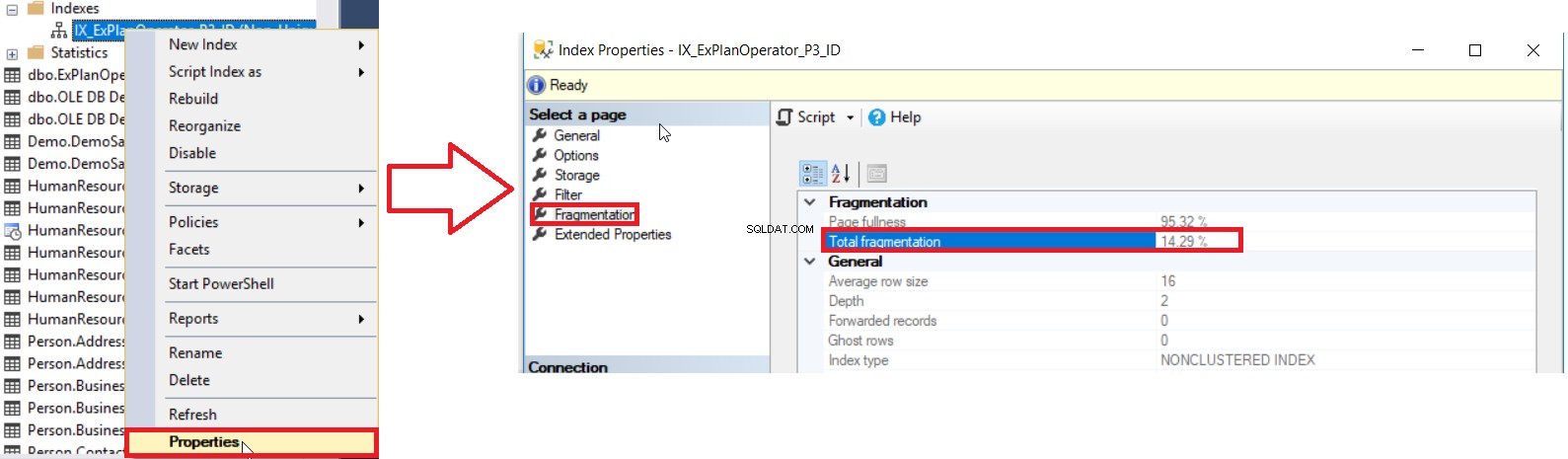
Mais pour vérifier le niveau de fragmentation de plusieurs index, vous devez d'abord effectuer la vérification de la méthode d'interface utilisateur pour tous les index, un par un, ce qui est une opération chronophage. La deuxième méthode disponible pour vérifier le niveau de fragmentation de tous les index de la base de données consiste à interroger le DMF sys.dm_db_index_physical_stats et à le joindre au DMV sys.indexes pour récupérer toutes les informations sur ces index, en tenant compte du fait que ces statistiques seront actualisées lorsque le Le service SQL Server est redémarré à l'aide d'une requête semblable à la suivante :
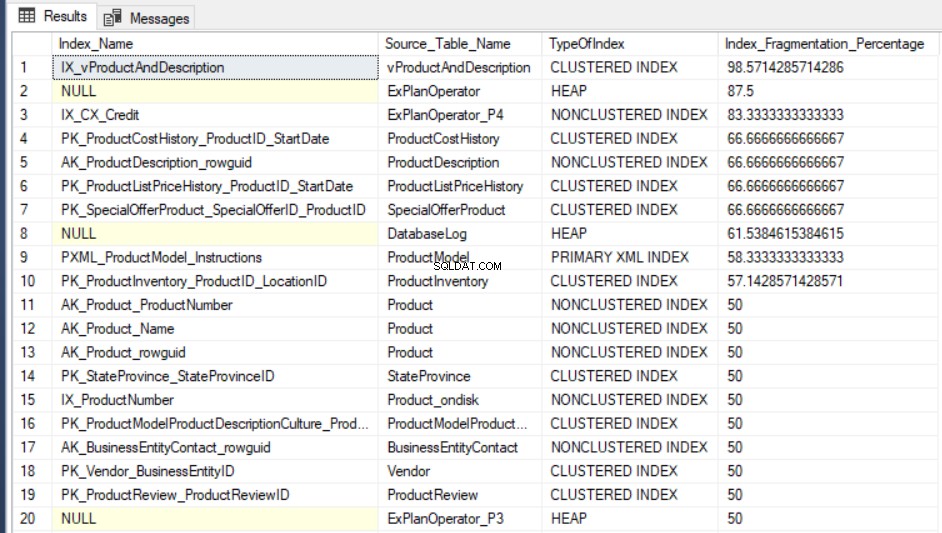
SELECT Indx.name AS Index_Name, OBJECT_NAME(Indx.OBJECT_ID) AS Source_Table_Name, Index_Stat.index_type_desc AS TypeOfIndex, Index_Stat.avg_fragmentation_in_percent Index_Fragmentation_Percentage FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) Index_Stat INNER JOIN sys.indexes Indx ON Indx.object_id = Index_Stat.object_id AND Indx.index_id = Index_Stat.index_id ORDER BY Index_Fragmentation_Percentage DESC
Le résultat de l'interrogation de AdventureWorks2016CTP3 la base de données de test ressemblera à ce qui suit :
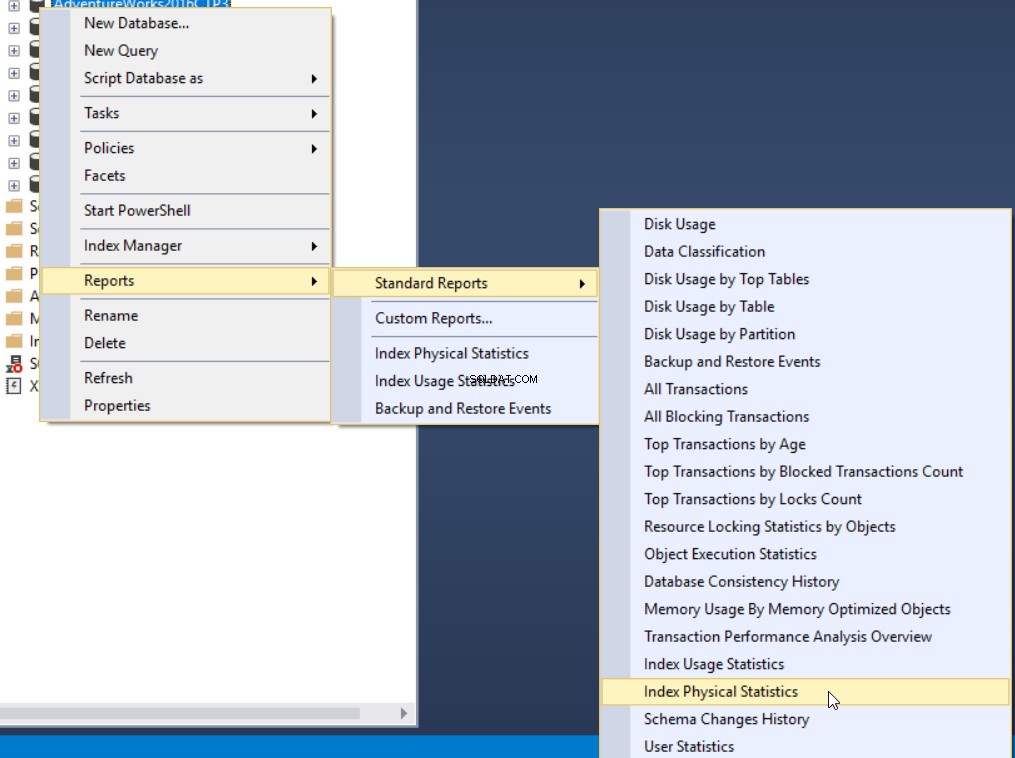
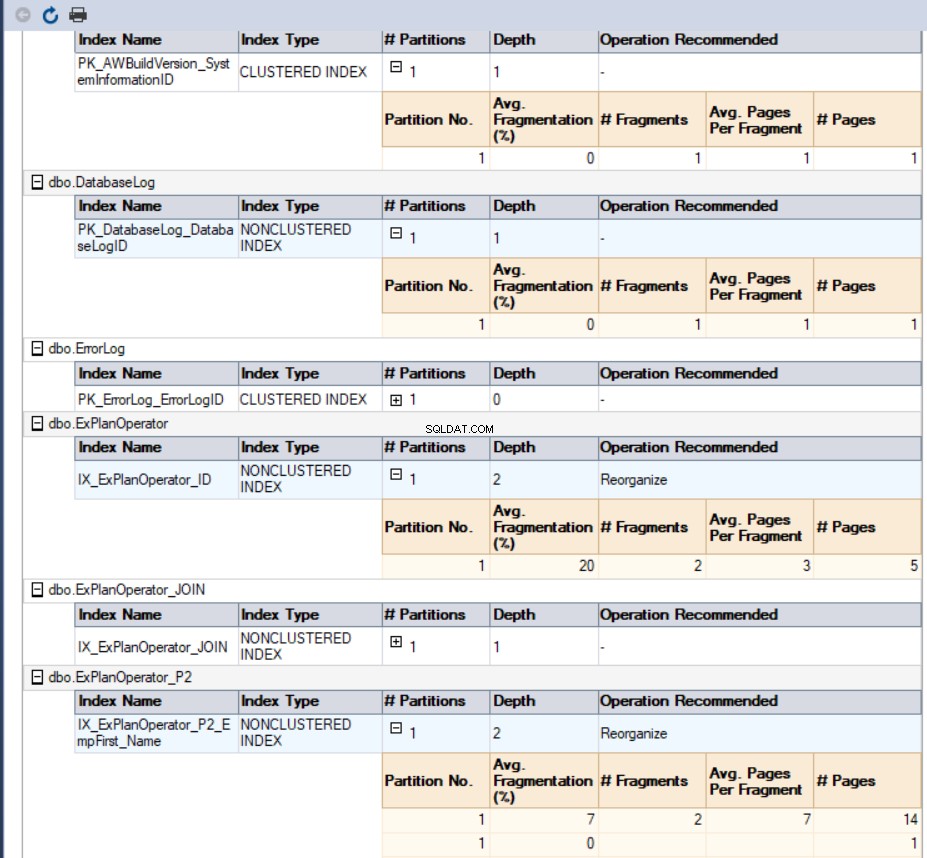
La troisième méthode pour obtenir le pourcentage de fragmentation consiste à utiliser le rapport standard intégré de SQL Server appelé Statistiques physiques d'index. Ce rapport renvoie des informations utiles sur les partitions d'index, le pourcentage de fragmentation, le nombre de pages sur chaque partition d'index et des recommandations sur la façon de résoudre le problème de fragmentation d'index en reconstruisant ou en réorganisant l'index. Pour afficher le rapport, cliquez avec le bouton droit sur votre base de données, sélectionnez l'option Rapports, Rapports standard et sélectionnez Indexer les statistiques physiques comme ci-dessous :
Dans notre cas, le rapport généré ressemblera à ceci :
Le dernier et le plus simple moyen de récupérer le pourcentage de fragmentation de tous les index de base de données est l'outil dbForge Index Manager. Le gestionnaire d'index dbForge est un complément qui peut être ajouté à votre SQL Server Management Studio pour analyser les index des bases de données SQL Server, vous fournissant un rapport très utile avec l'état des index de base de données sélectionnés et des suggestions de maintenance pour résoudre ces problèmes de fragmentation d'index.
Après avoir installé le complément dbForge Index Manager sur votre SSMS, vous pouvez l'exécuter en cliquant avec le bouton droit sur la base de données à analyser, sélectionnez Index Manager , puis Gérer la fragmentation de l'index comme indiqué ci-dessous :
L'outil dbForge Index Manager vous permet d'obtenir une image globale de la fragmentation des index de base de données sélectionnés, avec des recommandations sur les actions appropriées pour résoudre ce problème, comme indiqué ci-dessous :

L'outil dbForge Index Manager vous permet également de basculer entre les bases de données, vous fournissant un nouveau rapport après avoir scanné cette base de données comme indiqué ci-dessous :
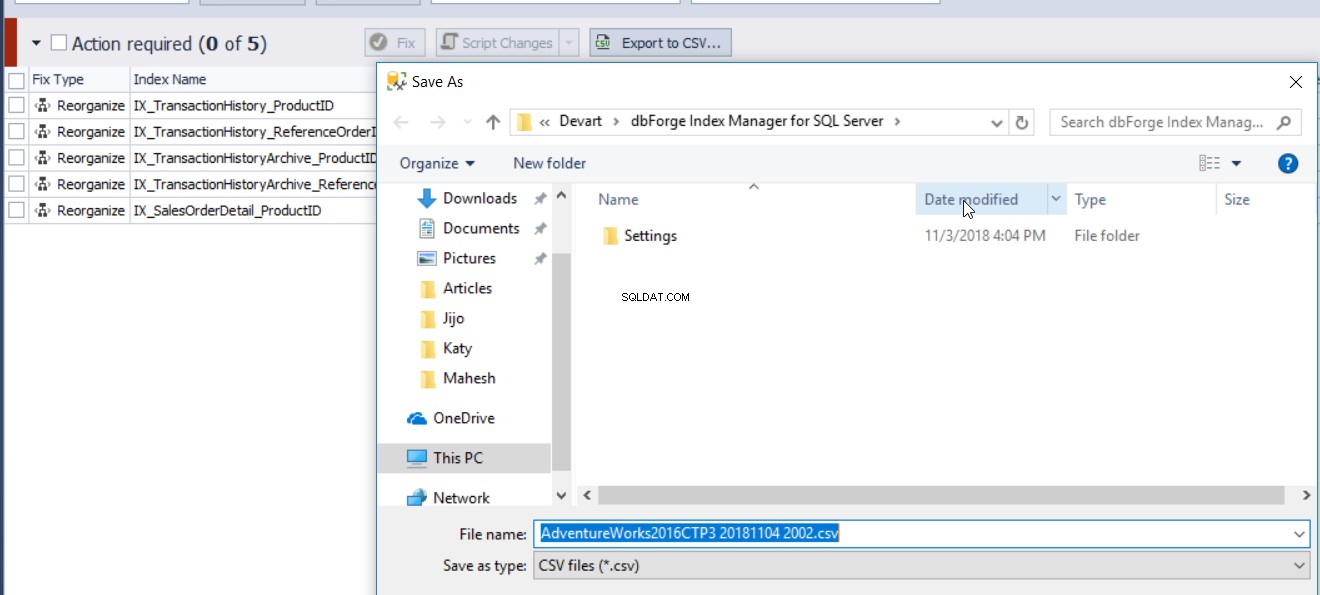
Le rapport de fragmentation d'index généré par l'outil dbForge Index Manager peut être exporté vers un fichier CSV afin d'analyser l'état de fragmentation des index, comme indiqué ci-dessous :
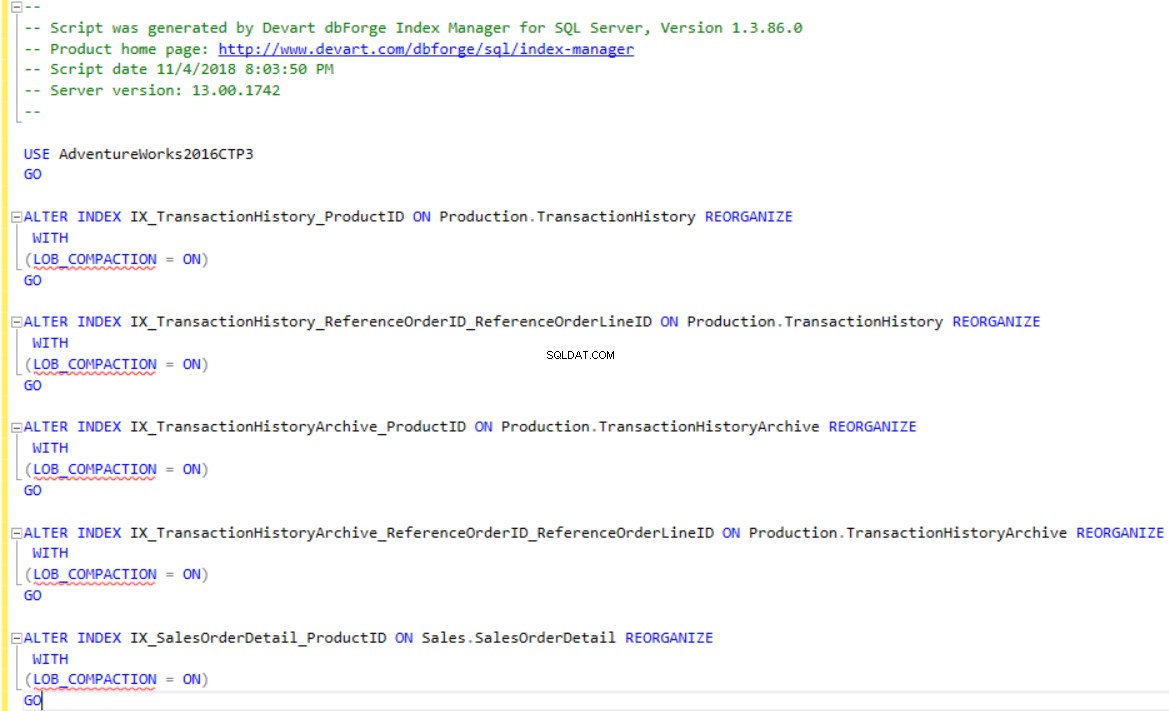
dbForge Index Manager vous permet de générer des scripts T-SQL pour reconstruire ou réorganiser les index selon les recommandations de l'outil. Utilisez les changements de script option pour afficher ou enregistrer le script pour les index fragmentés, comme indiqué ci-dessous :
L'outil dbForge Index Manager vous offre la possibilité de résoudre le problème de fragmentation d'index directement en cliquant sur Réparer bouton qui effectuera l'action recommandée directement sur les index sélectionnés, montrant l'état de la fixation sur le Résultat colonne comme indiqué ci-dessous :

Si vous cliquez sur Réanalyser , il analysera à nouveau la fragmentation de l'index sur la base de données après avoir effectué l'opération de correction avec succès. Ce qui est répertorié ici dans cet article n'est qu'une introduction à la manière dont l'outil dbForge Index Manager nous aidera à identifier et à résoudre les problèmes de fragmentation d'index. Ma recommandation pour vous est de le télécharger et de vérifier ce que cet outil peut vous offrir.
Liens utiles :
- Principes de base de l'index
- Types d'index
- Index cluster et non cluster décrits
- Structures d'index en cluster
Outil utile :
dbForge Index Manager - complément SSMS pratique pour analyser l'état des index SQL et résoudre les problèmes de fragmentation d'index.



