Dans mon article précédent, j'ai expliqué le processus d'installation et de création d'un cluster de basculement et comment activer le groupe de disponibilité AlwaysOn.
Dans cet article, je vais expliquer le processus de déploiement étape par étape des groupes de disponibilité SQL Server AlwaysOn à l'aide d'assistants. Les configurations de déploiement se présentent comme suit :

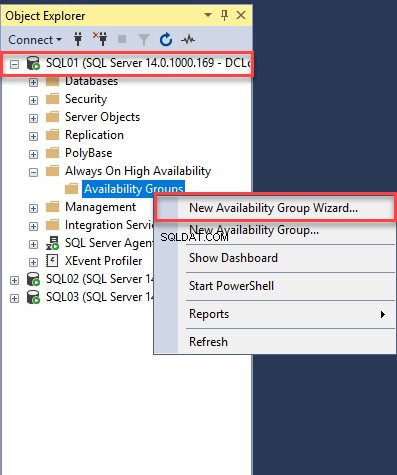
Nous avons installé SQL Server 2017 et SQL Server Management Studio sur tous les serveurs. Tout d'abord, connectez-vous à SQL01.DC.Local et ouvrez le studio de gestion SQL Server. Dans SSMS, connectez-vous au moteur de base de données. Dans la fenêtre de l'explorateur d'objets, développez AlwaysOn High Availability, cliquez avec le bouton droit sur les groupes de disponibilité et sélectionnez "Assistant Nouveau groupe de disponibilité". Voir l'image suivante :
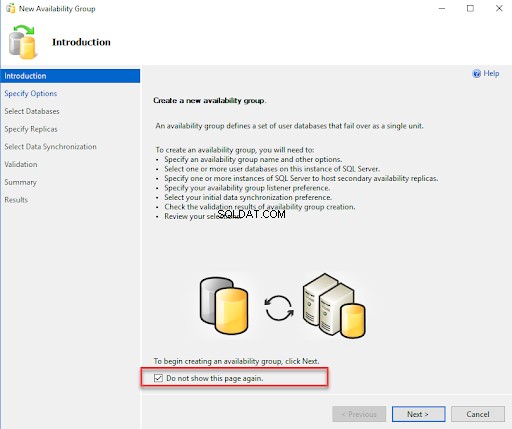
Le premier écran est Introduction, qui fournit les détails de l'assistant de groupe de disponibilité et les tâches que nous pouvons effectuer à l'aide de celui-ci. Si vous ne souhaitez plus voir cet écran, vous pouvez l'ignorer en sélectionnant "Ne plus afficher cette page. ” Cliquez sur Suivant pour passer à l'écran suivant. Voir la capture d'écran suivante :
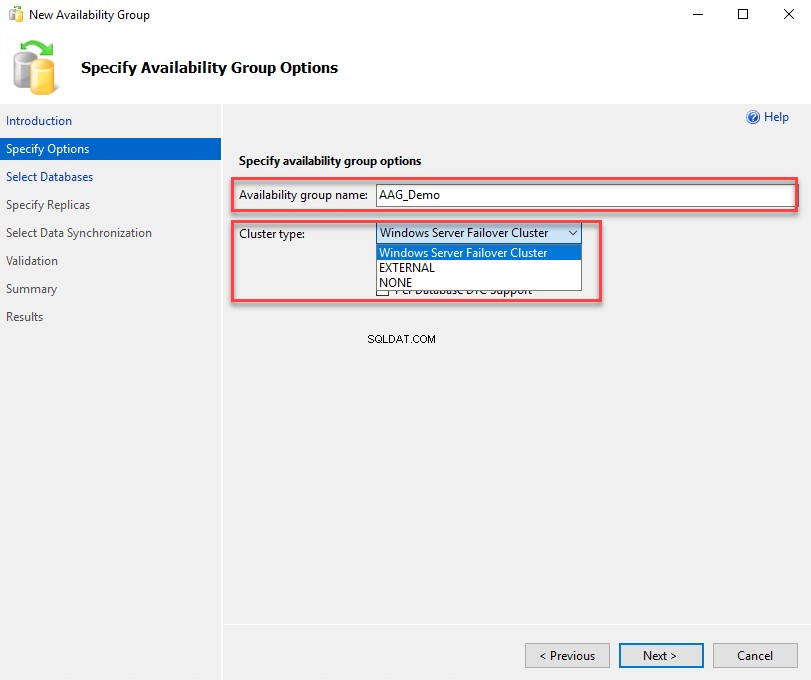
Sur l'écran Spécifier le groupe de disponibilité, entrez le nom souhaité du groupe de disponibilité. Dans le "Type de cluster ", vous pouvez choisir l'une des valeurs suivantes :
- Cluster de basculement Windows Server :Cette option est utilisée lorsque vous souhaitez créer un groupe de disponibilité à l'aide d'un cluster de basculement Windows Server traditionnel.
- Externe : Cette option est utilisée lorsque vous créez un groupe de disponibilité sur le système d'exploitation Linux. Il utilise le système d'exploitation Linux en l'intégrant à PACEMAKER (Gestionnaire de ressources Linux Cluster).
- AUCUN : Cette option est utilisée lorsque vous ne souhaitez pas activer l'option de haute disponibilité. Il peut être utilisé à la fois pour Windows et Linux.
Nous déployons AAG sur un cluster Windows, sélectionnez donc "Cluster de basculement Windows Server ” dans la liste déroulante des types de cluster. Cliquez sur Suivant pour passer à l'écran suivant. Voir la capture d'écran suivante :
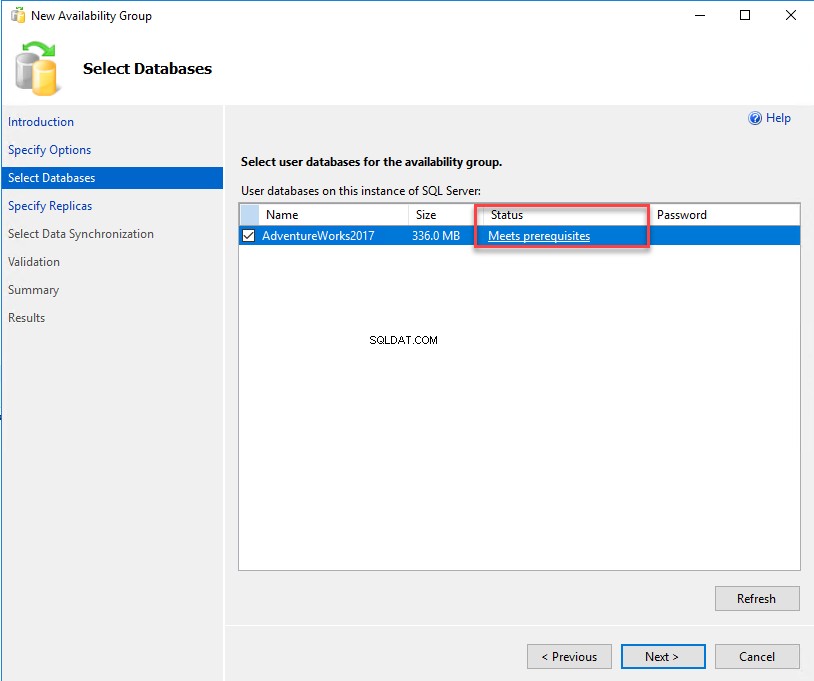
Sur le Sélectionner les bases de données l'écran, choisissez les bases de données que vous souhaitez inclure dans votre groupe de disponibilité. Les bases de données doivent remplir les conditions préalables suivantes pour faire partie du groupe de disponibilité :
- La base de données doit être dans le modèle de récupération complète.
- La sauvegarde complète de la base de données doit être effectuée.
Si les conditions préalables ci-dessus sont remplies, vous pouvez voir "Satisfait aux conditions préalables" dans le Statut colonne de la grille. Choisissez le nom de la base de données en cliquant sur la case à cocher et cliquez sur Suivant . Voir l'image suivante :
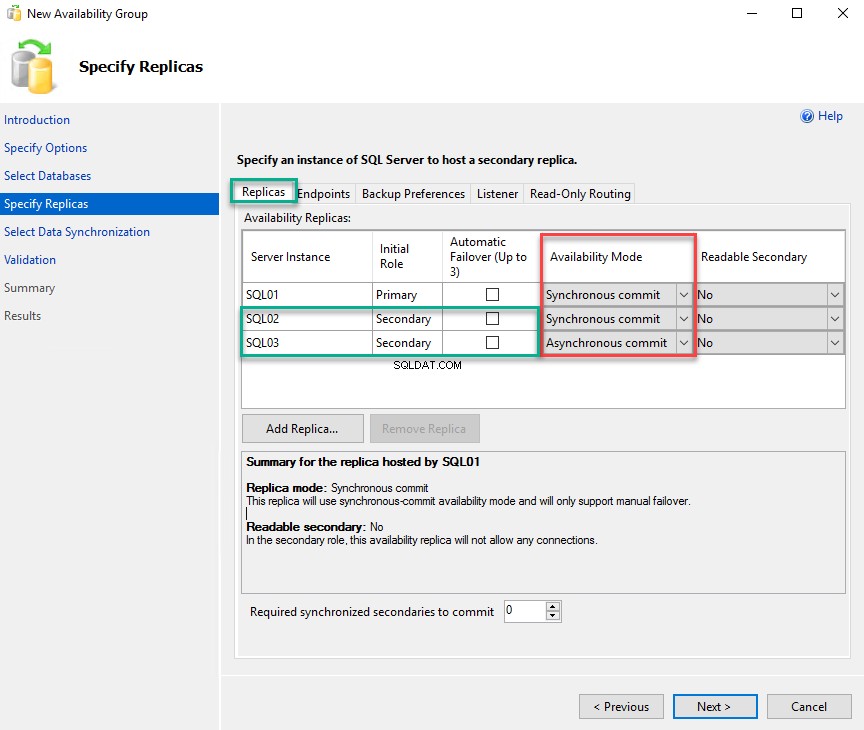
Sur le Spécifier le réplica l'écran, nous allons configurer les options suivantes :
- Liste des répliques disponibles.
- Points de terminaison.
- Préférence de sauvegarde.
- Écouteur de groupe de disponibilité.
- Routage en lecture seule.
Laissez-moi vous expliquer toutes les options.
Tout d'abord, dans la réplique , vous pouvez spécifier la liste des réplicas que vous souhaitez inclure dans le groupe de disponibilité. Nous allons inclure SQL02.Dc.Local et SQL03.DC.Local en tant que répliques secondaires. Pour ajouter une réplique, cliquez sur "Ajouter une réplique " bouton.
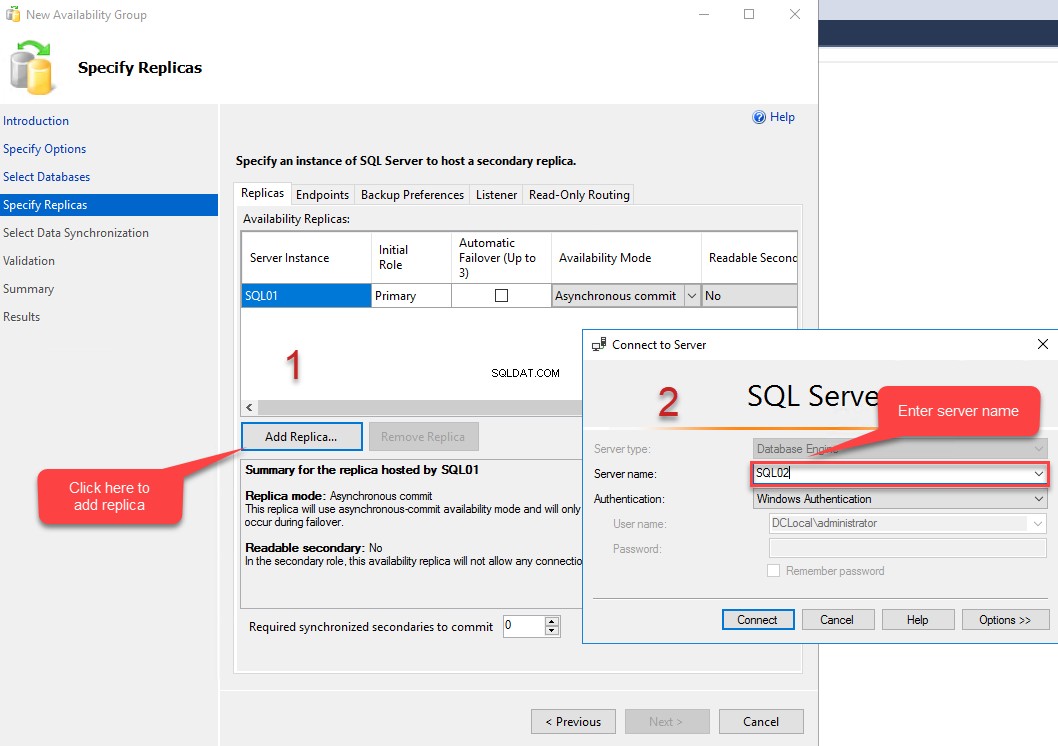
Lorsque vous cliquez sur "Ajouter un réplica ”, le Se connecter au serveur boîte de dialogue s'ouvre. Dans la zone de texte Nom du serveur, saisissez le nom du serveur que vous souhaitez ajouter au groupe de disponibilité, puis cliquez sur Se connecter . Ajouter SQL02 dans la zone de texte du nom du serveur et cliquez sur Se connecter . De même, ajoutez SQL03.Dc.Local dans les réplicas de disponibilité. Comme je l'ai mentionné au début de l'article, SQL02.Dc.Local sera le réplica synchrone et SQL03.Dc.Local sera le réplica asynchrone ; par conséquent, choisissez Synchronous pour valider à partir du mode de colonne du mode de disponibilité pour SQL02.Dc.Local et choisissez Commit asynchrone pour SQL03.Dc.Local . Voir l'image suivante :
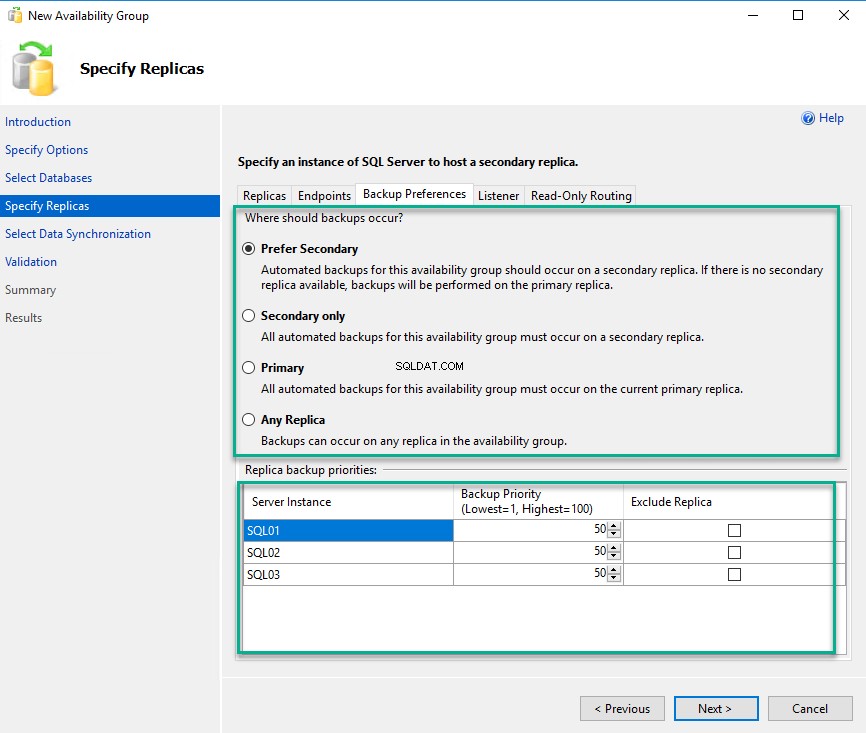
Pour configurer la préférence de sauvegarde, cliquez sur Préférence de sauvegarde languette. Dans l'écran des préférences de sauvegarde, vous pouvez voir quatre options. Les détails de chaque option sont fournis sur l'écran, qui est explicite. Comme je l'ai mentionné, choisissez le "Préférer le secondaire " option. La priorité de sauvegarde apparaît lorsque vous avez configuré le groupe de disponibilité avec plusieurs réplicas secondaires et que la préférence de sauvegarde est secondaire. La priorité de sauvegarde sera déterminée en fonction du nombre entré dans la zone de texte de priorité de sauvegarde. Par exemple, si la priorité de sauvegarde est 70 pour le SQL03.Dc.Local réplique, la sauvegarde sera générée sur le SQL03.Dc.Local réplique. Si vous ne souhaitez pas générer de sauvegarde sur une réplique spécifique, vous pouvez exclure une réplique en cliquant sur "Exclure la réplique ” case à cocher. Pour l'instant, n'apportez aucune modification à la priorité de sauvegarde. Voir l'image suivante :
Pour créer un écouteur de groupe de disponibilité, cliquez sur l'onglet Écouteur. Dans l'onglet écouteur, sélectionnez "créer un nouvel écouteur de disponibilité. » Dans la zone de texte Nom DNS, indiquez le nom DNS souhaité. Ce nom DNS sera utilisé pour se connecter au groupe de disponibilité. Entrez le port souhaité dans la boîte de dialogue Numéro de port. Assurez-vous que le port est ouvert dans le pare-feu Windows. Choisissez Adresse IP statique du Réseau liste déroulante des modes. Cliquez sur le bouton Ajouter pour ajouter une adresse IP. Lorsque vous cliquez sur Ajouter, le message "Ajouter une adresse IP » la boîte de dialogue s'ouvre. Dans la boîte de dialogue, entrez l'adresse IP souhaitée. Cliquez sur OK pour fermer la boîte de dialogue. Voir l'image suivante :
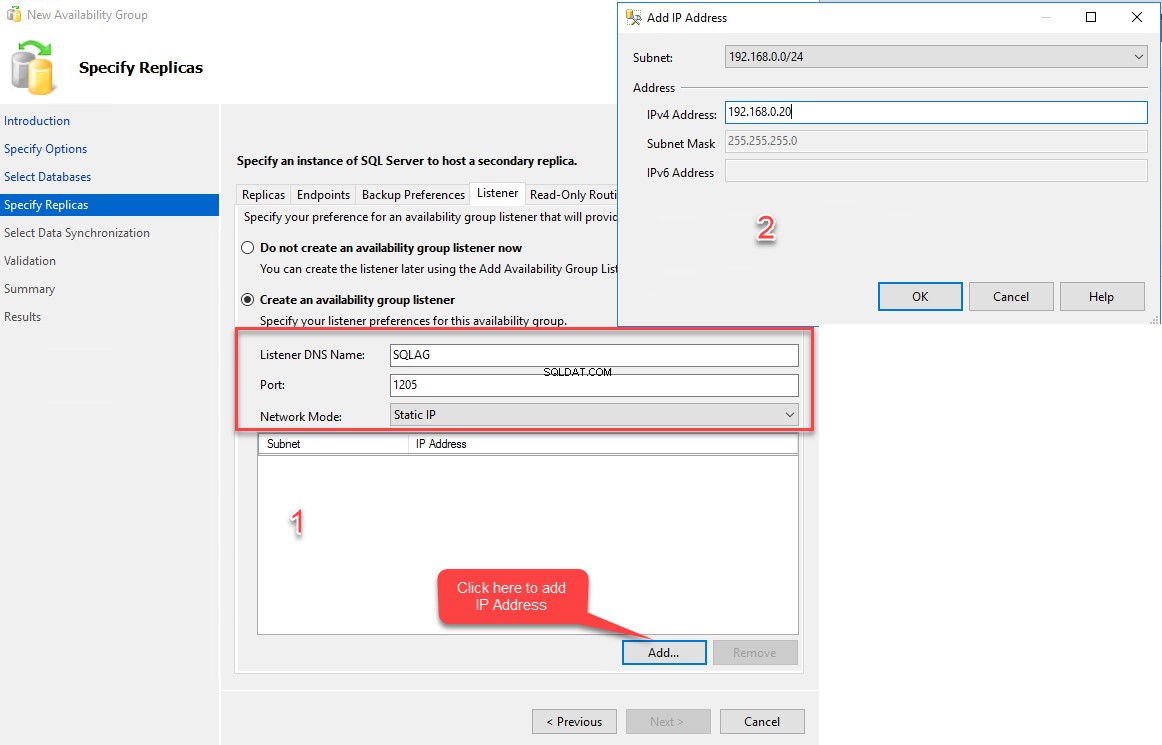
Une fois tous les paramètres configurés, cliquez sur Suivant . Dans l'onglet "Sélectionner la synchronisation initiale des données ", vous pouvez voir plusieurs options. Ils se présentent comme suit :
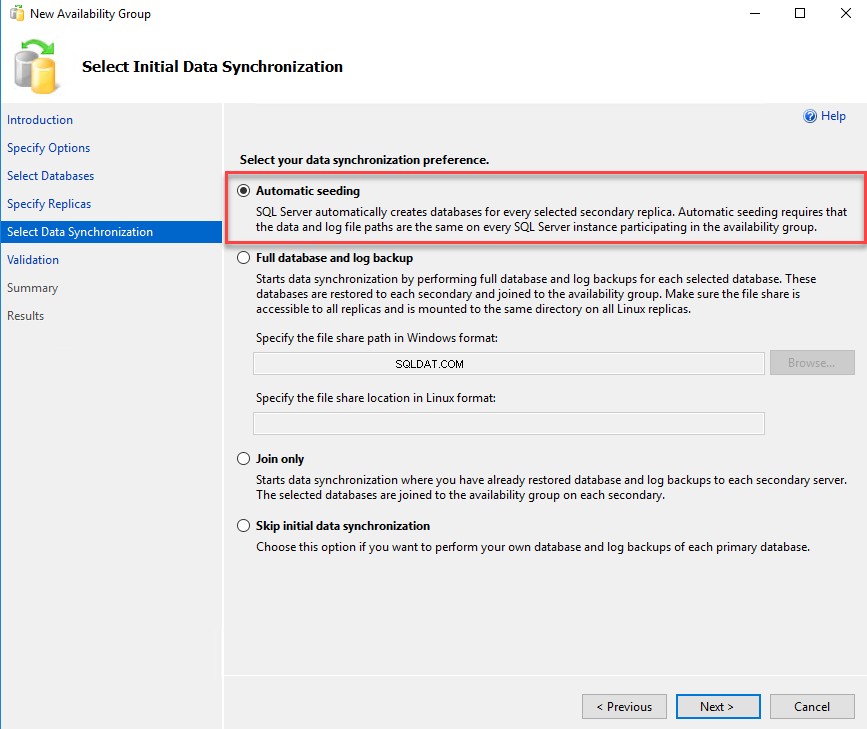
Répartition automatique : Lorsque vous choisissez cette option, l'assistant crée automatiquement une base de données de disponibilité sur tous les réplicas secondaires. Pour utiliser cette option, nous devons nous assurer que les chemins d'accès au fichier de données et au fichier journal sont les mêmes sur tous les réplicas principaux et secondaires.
Sauvegarde complète de la base de données et du journal : Lorsque vous choisissez cette option, l'assistant restaure les sauvegardes complètes de la base de données et du journal pour les bases de données disponibles à partir d'emplacements partagés saisis dans la zone de texte "Chemin de partage de fichiers". Pour utiliser cette option, nous devons créer un dossier partagé pour conserver les sauvegardes complètes de la base de données et des journaux. Votre compte de service SQL Server doit disposer d'une autorisation de lecture-écriture sur le dossier partagé.
Rejoindre uniquement : Lorsque vous choisissez cette option, l'assistant rejoint une base de données de disponibilité créée sur tous les réplicas secondaires. Pour utiliser cette option, nous devons restaurer une sauvegarde de la base de données de disponibilité sur tous les réplicas secondaires.
Ignorer la synchronisation initiale : Lorsque vous choisissez cette option, l'assistant ignore la synchronisation initiale des réplicas principal et secondaire. Nous pouvons le faire manuellement.
Dans notre configuration de démonstration, les emplacements des fichiers de données et des fichiers journaux sont les mêmes ; par conséquent, choisissez l'option "Amorçage automatique" dans la "préférence de synchronisation des données ", puis cliquez sur Suivant . Voir l'image suivante :
Sur l'écran de validation, l'assistant effectuera des contrôles de validation sur l'ensemble de la configuration. Il doit être passé avec succès. Si vous rencontrez une erreur lors du test de validation, vous devez la corriger et cliquer sur "réexécuter la validation ” pour revalider la configuration. Une fois le test de validation passé avec succès, cliquez sur Suivant . Voir l'image suivante :
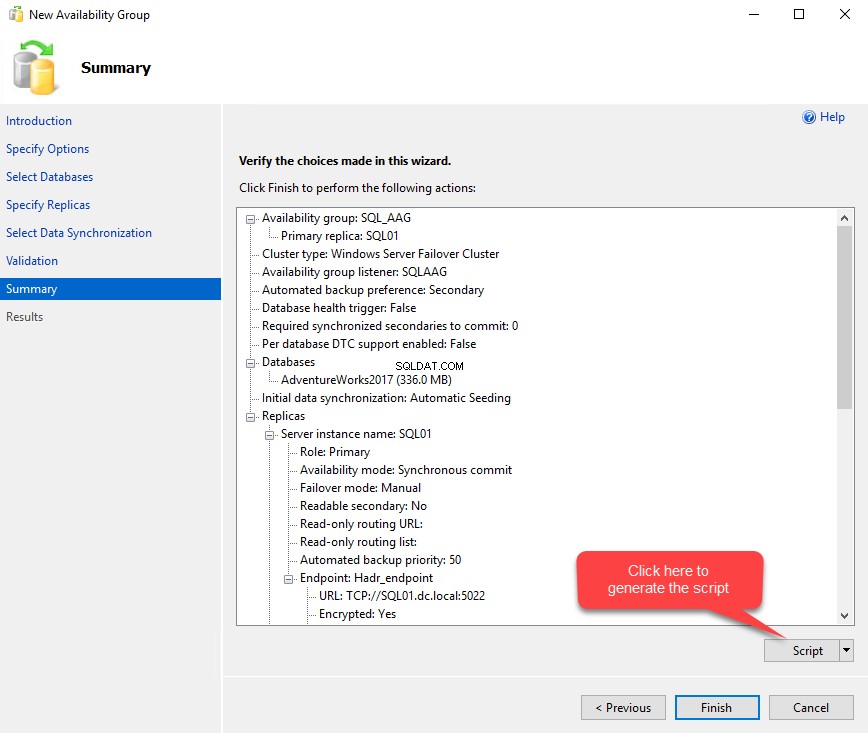
Sur le Résumé l'écran, passez en revue l'ensemble de la configuration des paramètres et cliquez sur Terminer bouton. Une fois que vous aurez cliqué sur le bouton Terminer, l'assistant lancera le processus de création d'un groupe de disponibilité. Vous pouvez également générer un script pour celui-ci en cliquant sur le bouton "Script". Voir l'image suivante :
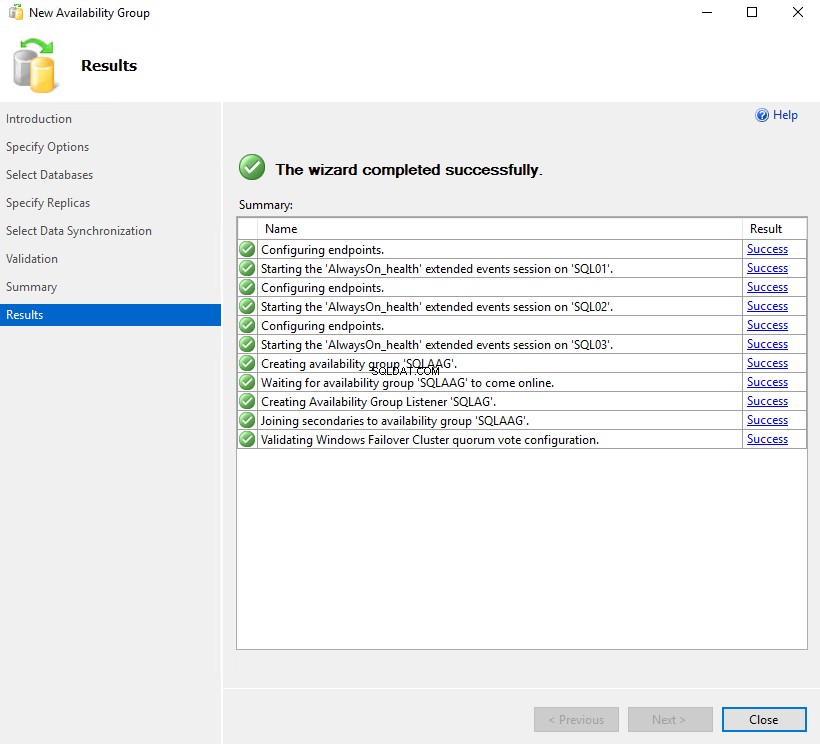
Toutes nos félicitations. Nous avons créé avec succès le groupe de disponibilité AlwaysOn. Voir l'image suivante :
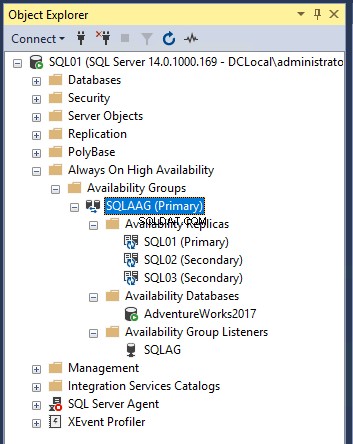
Pour afficher les détails du groupe de disponibilité, développez AlwaysOn High Availability dans l'explorateur d'objets ? Développer le groupe de disponibilité . Vous pouvez voir que le groupe de disponibilité nommé "SQL_AAG" a été créé. Pour afficher le nœud participant, développez SQL_AAG ? Développer le réplica de disponibilité . Pour afficher les bases de données de disponibilité, développez Bases de données de disponibilité . Et pour afficher l'écouteur, développez Écouteur du groupe de disponibilité . Voir l'image suivante :
Résumé
Dans cet article, j'ai expliqué le processus de déploiement étape par étape du groupe de disponibilité AlwaysOn à l'aide de A Assistant de groupe de disponibilité lwaysOn . Dans le prochain article, j'expliquerai différentes manières de surveiller le groupe de disponibilité AlwaysOn. Je vais également démontrer le processus de basculement et expliquer le routage en lecture seule. Cependant, un bel article couvrant ce sujet a été écrit par Ganapathi Varma Chekuri sur C bonne vue. Vous pouvez lire l'article ici.
Restez à l'écoute !