Cet article se concentrera sur l'utilisation des JOIN. Nous allons commencer par parler un peu de la façon dont les JOIN vont se produire et pourquoi vous avez besoin de données JOIN. Ensuite, nous examinerons les types de JOIN dont nous disposons et comment les utiliser.
JOINDRE LES BASES
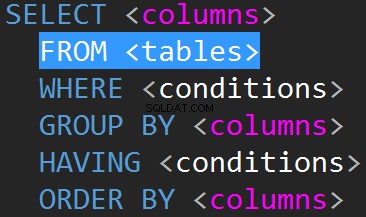
Les JOIN dans TSQL sont généralement effectués sur la ligne FROM.
Avant de passer à autre chose, la vraie grande question devient - "Pourquoi devons-nous faire des JOIN, et comment allons-nous réellement effectuer nos JOIN?"
Il s'avère que chaque base de données avec laquelle nous travaillons verra ses données divisées en plusieurs tables. Il y a plusieurs raisons à cela :
- Maintenir l'intégrité des données
- Économie d'espace stocké
- Modifier les données plus rapidement
- Rendre les requêtes plus flexibles
Ainsi, chaque base de données avec laquelle vous allez travailler aura besoin que ces données soient réunies pour que cela ait un sens.
Par exemple, vous avez des tables distinctes pour les commandes et pour les clients. La question qui devient - "Comment connectons-nous réellement toutes les données ensemble?" C'est exactement ce que les JOIN vont faire.
COMMENT FONCTIONNENT LES JOINS
Imaginez le cas, lorsque nous avons deux tables distinctes et que ces tables vont être réunies en créant une couture.
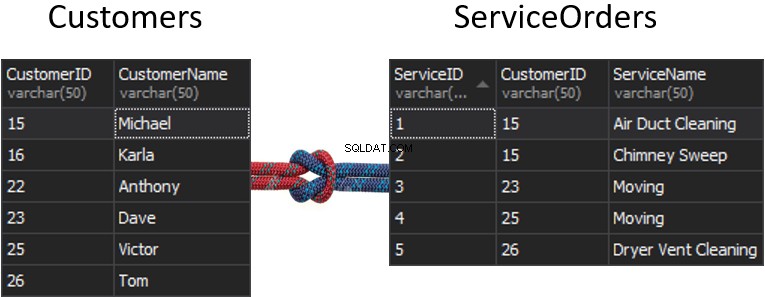
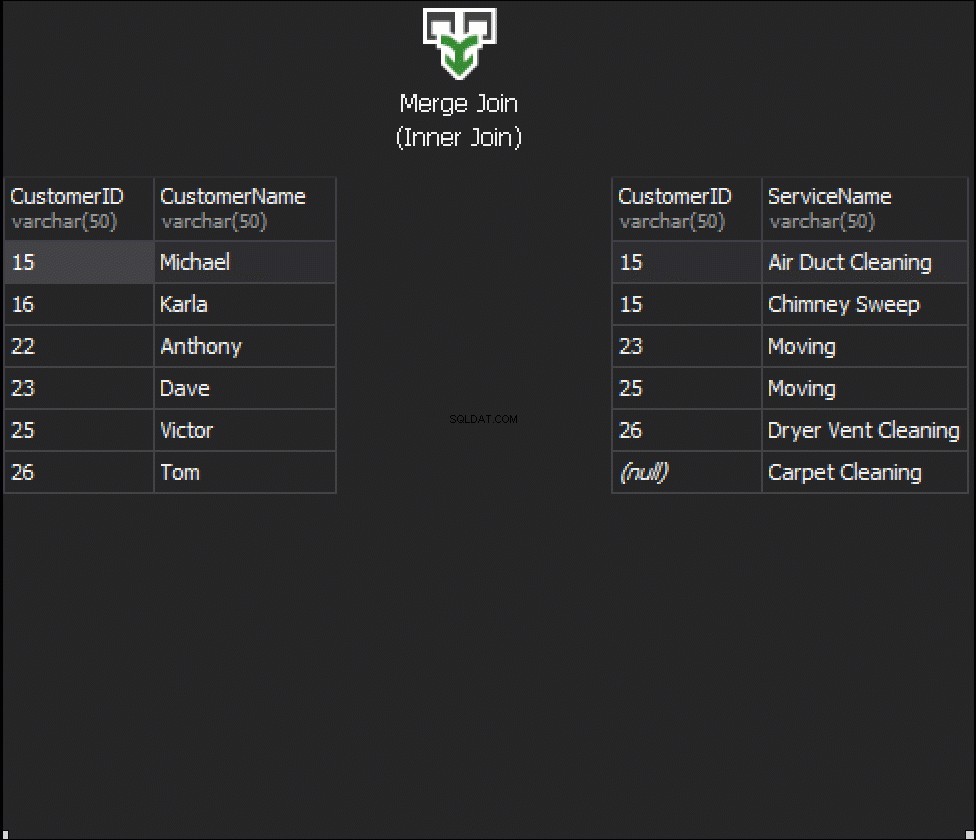
Que va-t-il se passer avec la couture, si nous obtenons une colonne de chaque table qui va être utilisée pour la correspondance, et qui va déterminer quelles lignes seront ou ne seront pas retournées ? Par exemple, nous avons Customers à gauche et ServiceOrders à droite. Si nous voulons obtenir tous les clients et leurs commandes, nous devons JOINDRE ces deux tables ensemble. Pour cela, nous devons choisir une colonne qui agira comme une couture, et évidemment, bien sûr, la colonne que nous allons utiliser est CustomerID.
Soit dit en passant, le CustomerID est connu sous le nom de clé primaire pour la table de gauche, qui identifie de manière unique chaque ligne à l'intérieur de la table Customers.
Dans la table ServiceOrders, nous avons également la colonne CustomerID, connue sous le nom de Foreign Key . Une clé étrangère est simplement une colonne conçue pour pointer vers une autre table. Dans notre cas, il pointe vers la table Customers. Par conséquent, c'est ainsi que nous allons rassembler toutes ces données en fournissant cette couture.
Dans ces tableaux, nous avons les correspondances suivantes :2 commandes pour 15 et 1 commande pour 23, 25 et 26. 16 et 22 sont omis.
Une chose importante à noter ici est que nous pouvons JOINDRE plusieurs tables . En fait, il est assez courant de JOINDRE plusieurs tables ensemble, afin d'obtenir toute forme d'information. Si vous jetez un coup d'œil à la base de données la plus courante, vous devrez peut-être JOINDRE quatre, cinq, six tables et plus juste pour obtenir les informations que vous recherchez. Avoir un diagramme de base de données va être utile.
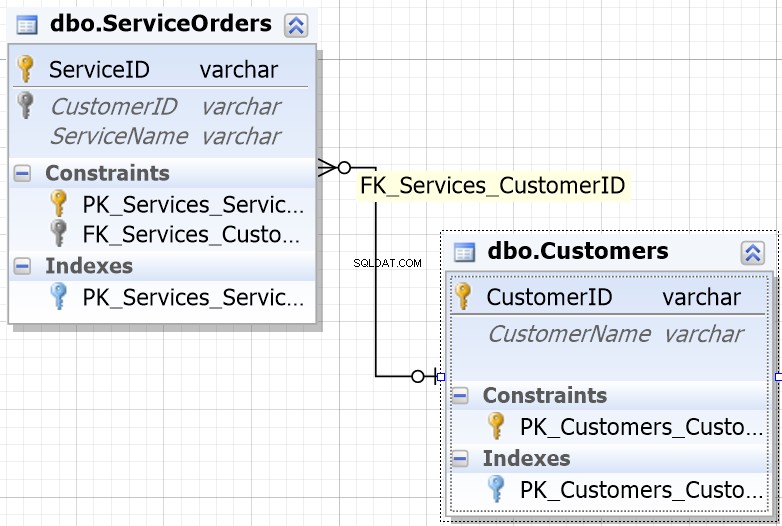
Pour vous aider dans la plupart des environnements de base de données, vous remarquerez que les colonnes conçues pour être jointes ont le même nom.
JOIN SYNTAX
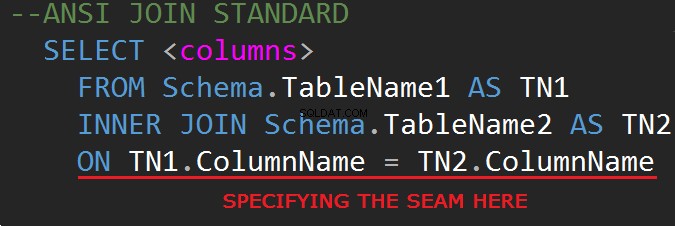
La troisième révision du langage de requête de base de données SQL (SQL-92) réglemente la syntaxe JOIN :
Il est possible de faire des JOIN sur la ligne WHERE :
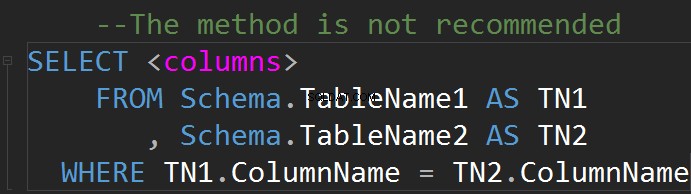
Une relation a généralement une interprétation graphique simple sous forme de tableau.
Bonnes pratiques et conventions
- Noms de table d'alias.
- Utiliser un nom en deux parties pour les colonnes
- Placez chaque JOIN sur une ligne distincte
- Placer les tableaux dans un ordre logique
TYPES DE JOINTS
SQL Server fournit les types de JOIN suivants :
- JOINTURE INTERNE
- JOINTURE EXTERNE
- AUTO-JOINTURE
- JOINTURE CROISÉE
Pour plus d'informations sur le sujet, n'hésitez pas à consulter cet article sur les types de jointures dans SQL Server et découvrez à quel point il est facile d'écrire de telles requêtes à l'aide de SQL Complete.
JOINTURE INTERNE
Le premier type de JOIN que nous pouvons vouloir exécuter est le INNER JOIN. Habituellement, les auteurs se réfèrent à ce type de JOIN SQL Server en tant que JOIN normal ou simple. Ils omettent simplement le préfixe INNER. Ce type de JOIN combine deux tables ensemble et ne renvoie que les lignes des deux côtés qui correspondent .
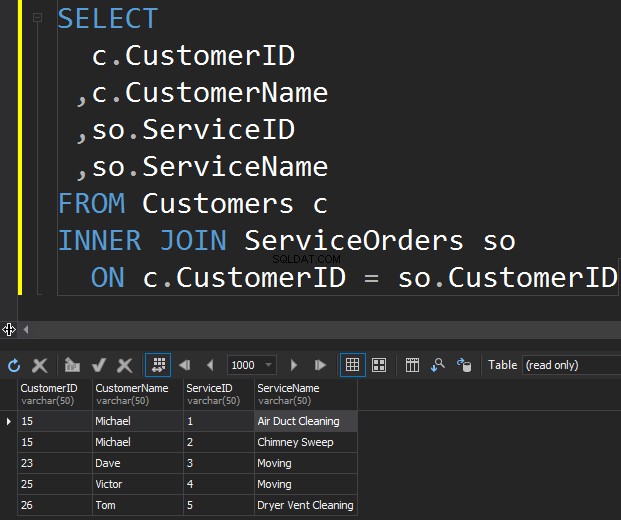
Nous ne voyons pas Klara et Anthony ici car leur CustomerID ne correspond pas dans les deux tables. Je tiens également à souligner le fait que l'opération JOIN renvoie un client chaque fois qu'il correspond à la commande . Il y a deux commandes pour Michael et une commande pour Dave, Victor et Tom chacun.
Résumé :
- INNER JOIN renvoie des lignes uniquement lorsqu'il y a au moins une ligne dans les deux tables qui correspond à la condition JOIN.
- INNER JOIN élimine les lignes qui ne correspondent pas à une ligne de l'autre table
JOINTURE EXTERNE
Les jointures externes sont différentes car elles renvoient des lignes de tables ou de vues même si elles ne correspondent pas. Ce type de JOIN est utile si vous avez besoin de récupérer tous les clients qui n'ont jamais passé de commande. Ou, par exemple, si vous recherchez un produit qui n'a jamais été commandé.
La façon dont nous faisons nos OUTER JOIN est en indiquant LEFT ou RIGHT, ou FULL.
Il n'y a aucune différence entre les clauses suivantes :
- JOINTURE EXTERNE GAUCHE =JOINTURE GAUCHE
- JOINTURE EXTERNE DROITE =JOINTURE DROITE
- JOINTURE EXTERNE COMPLÈTE =JOINTURE COMPLÈTE
Cependant, je recommanderais d'écrire la clause complète car cela rend le code plus lisible.
Utilisation de JOINTURE EXTERNE GAUCHE
Il n'y a pas de différence entre LEFT ou RIGHT, sauf le fait que nous pointons simplement la table à partir de laquelle nous voulons obtenir les lignes supplémentaires. Dans l'exemple suivant, nous avons répertorié les clients et leurs commandes. Nous utilisons la GAUCHE pour obtenir tous les clients qui n'ont jamais passé de commande. Nous demandons à SQL Server de nous obtenir des lignes supplémentaires à partir de la table de gauche.
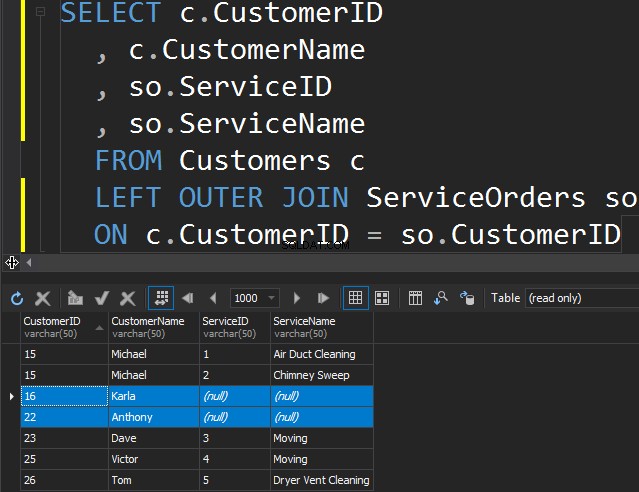
Notez que Karla et Anthony n'ont passé aucune commande et, par conséquent, nous obtenons des valeurs NULL pour ServiceName et ServiceID. SQL Server ne sait pas quoi placer là-dedans et place des valeurs NULL.
Utiliser RIGHT OUTER JOIN
Pour obtenir le service le moins populaire de la table ServiceOrders, nous devons utiliser la BONNE direction.
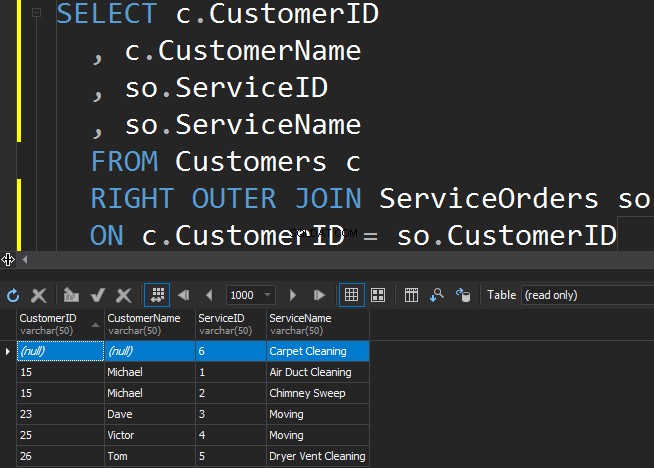
Nous voyons que dans ce cas, SQL Server a renvoyé des lignes supplémentaires à partir de la table de droite et que le service de nettoyage de tapis n'a jamais été commandé.
Utiliser la JOINTURE EXTERNE COMPLÈTE
Ce type de JOIN vous permet d'obtenir les informations non concordantes en incluant des lignes non concordantes des deux tables.
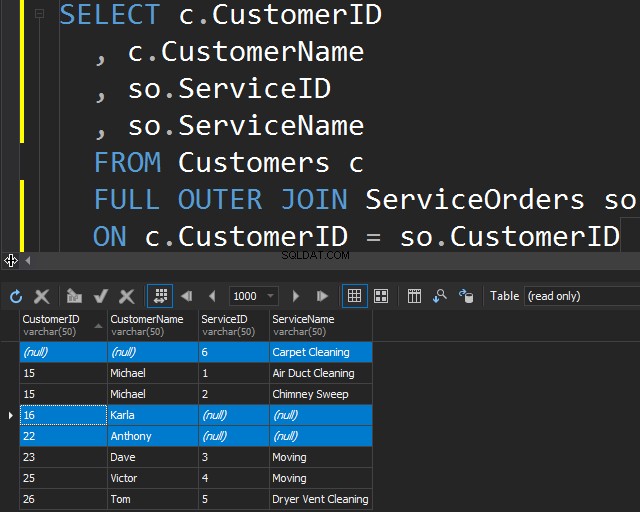
Cela peut également être utile si vous devez effectuer un nettoyage des données.
Résumé :
JOINT EXTERNE COMPLET
- Renvoie les lignes des deux tables même si elles ne correspondent pas à l'instruction JOIN
GAUCHE ou DROITE
- Aucune différence sauf dans l'ordre des tables dans la clause FROM
- Points de direction vers une table à partir de laquelle récupérer les lignes non correspondantes
AUTO-JOINTURE
Le prochain type de JOIN que nous avons est SELF JOIN. C'est probablement le deuxième type de JOIN le moins courant que vous allez exécuter. Un SELF JOIN, c'est quand vous joignez une table sur elle-même. D'une manière générale, c'est un signe de mauvaise conception. Pour utiliser la même table deux fois dans une même requête, la table doit avoir un alias. L'alias aide le processeur de requêtes à identifier si les colonnes doivent présenter les données du côté droit ou du côté gauche. De plus, vous devez éliminer les rangées qui marchent elles-mêmes. Cela se fait généralement avec une jointure non-équi.
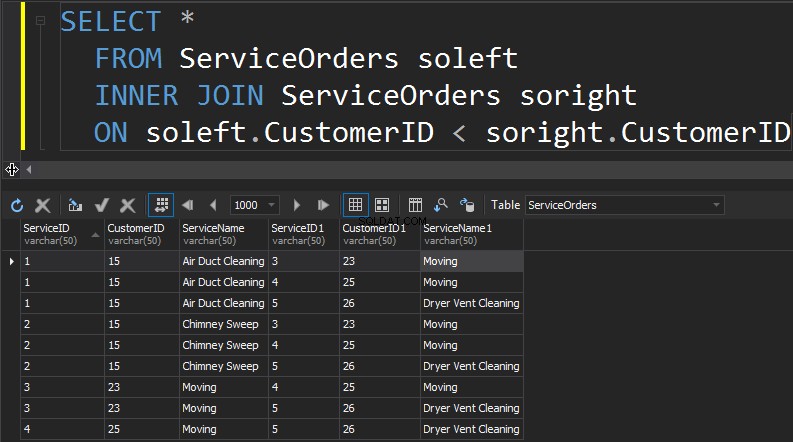
Résumé :
- JOIN une table à elle-même
- Généralement un signe de mauvaise conception et de normalisation
- Les tables doivent avoir un alias
- Besoin de filtrer les lignes qui se correspondent
JOINTURES CROISÉES
Ce type de JOIN n'a pas le ON déclaration. Chaque ligne de chaque table va correspondre. Ceci est également connu sous le nom de produit cartésien (dans le cas où un CROSS JOIN n'a pas de clause WHERE). Vous n'utiliserez guère ce type JOIN dans des scénarios réels, cependant, c'est un bon moyen de générer des données de test.
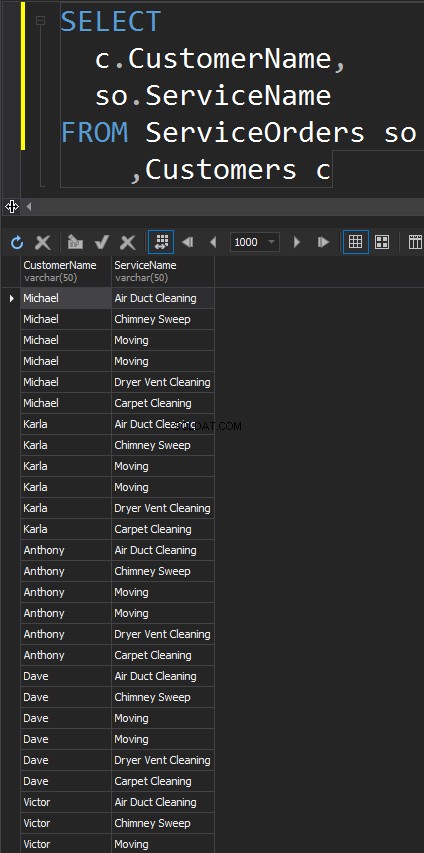
Le résultat est un ensemble de données, où le nombre de lignes dans la table de gauche est multiplié par le nombre de lignes dans la table de droite. Finalement, nous constatons que chaque client correspond à chaque service.
Nous obtenons le même résultat en utilisant explicitement la clause CROSS JOIN.
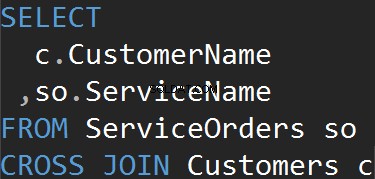
Résumé :
- Toutes les lignes correspondent dans chaque tableau
- Pas d'instruction ON
- Peut être utilisé pour générer des données de test
JOINDRE DES ALGORITHMES
Dans la première partie de l'article, nous avons discuté de la logique Opérateurs JOIN que SQL Server utilise lors de l'analyse et de la liaison des requêtes. Ce sont :
- JOINTURE INTERNE
- JOINTURE EXTERNE
- JOINTURE CROISÉE
Les opérateurs logiques sont conceptuels et ils diffèrent des opérateurs physiques JOIN. Autrement dit, les JOIN logiques ne se joignent pas réellement colonnes de table particulières. Un seul JOIN logique peut correspondre à plusieurs JOIN physiques. SQL Server remplace les jointures logiques par des jointures physiques lors de l'optimisation. SQL Server possède les opérateurs JOIN physiques suivants :
- boucle imbriquée
- FUSIONNER
- HAS
Un utilisateur n'écrit ni n'utilise ces types de JOINS. Ils font partie du moteur SQL Server et SQL Server les utilise en interne pour implémenter des jointures logiques. Lorsque vous explorez le plan d'exécution, vous remarquerez peut-être que SQL Server remplace les opérateurs JOIN logiques par l'un des trois opérateurs physiques.
Joindre une boucle imbriquée
Commençons par l'opérateur le plus simple, Nested Loop. L'algorithme compare chaque ligne d'une table (table externe) à chaque ligne de l'autre table (table interne) à la recherche de lignes qui répondent au prédicat JOIN.
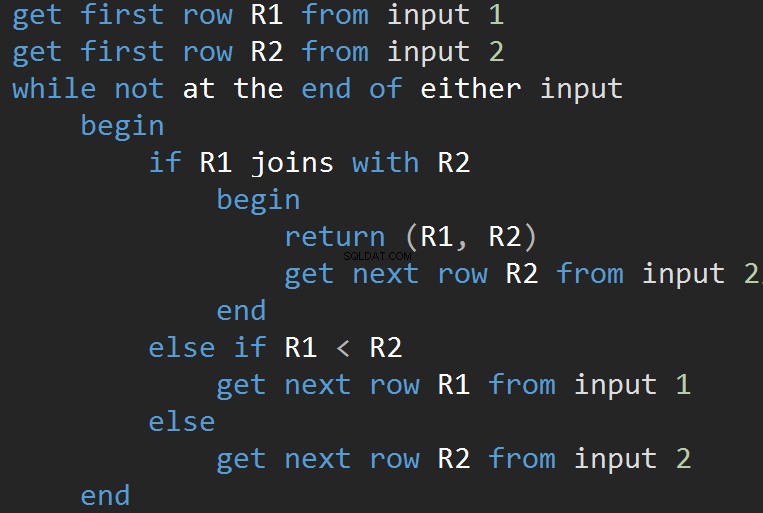
Le pseudo-code suivant décrit l'algorithme de boucle de jointure imbriquée interne :

Le pseudo-code suivant décrit l'algorithme de boucle de jointure imbriquée externe :
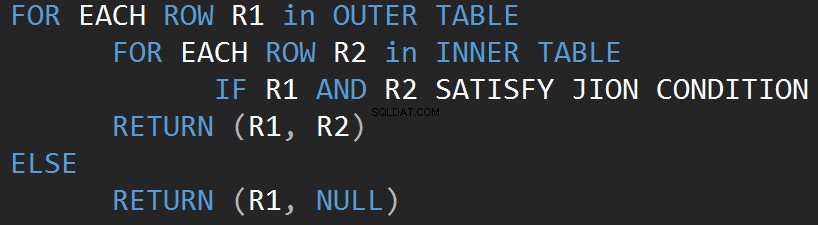
La taille de l'entrée affecte directement le coût de l'algorithme. L'intrant augmente, le coût augmente également. Ce type d'algorithme JOIN est efficace en cas de petite entrée. SQL Server estime un prédicat JOIN pour chaque ligne dans les deux entrées.
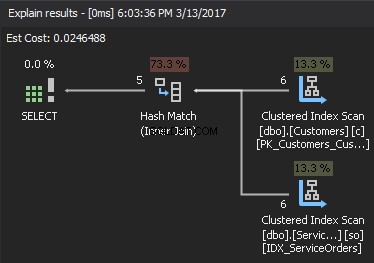
Considérez la requête suivante comme exemple, qui obtient les clients et leurs commandes.
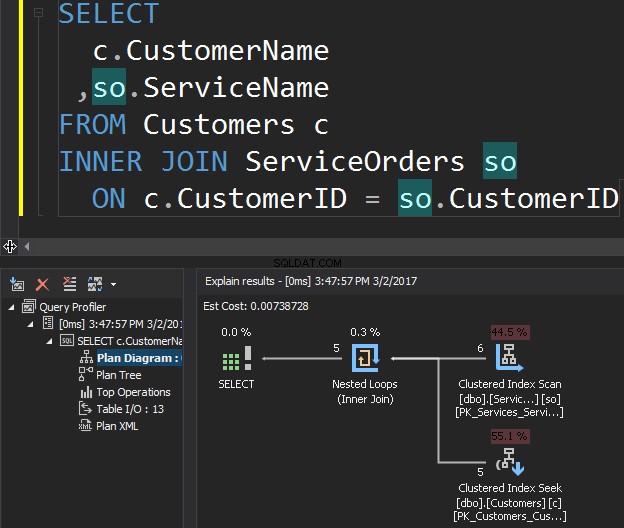
L'opérateur Clustered Index Scan est l'entrée externe et la recherche d'index clusterisée est l'entrée interne . L'opérateur Nested Loop trouve en fait la correspondance. L'opérateur recherche chaque enregistrement dans l'entrée externe et trouve les lignes correspondantes dans l'entrée interne. SQL Server exécute l'opération Clustered Index Scan (entrée externe) une seule fois pour obtenir tous les enregistrements pertinents. Clustered Index Seek est exécuté pour chaque enregistrement à partir de l'entrée externe. Pour le confirmer, placez le curseur sur l'icône de l'opérateur et examinez l'info-bulle.
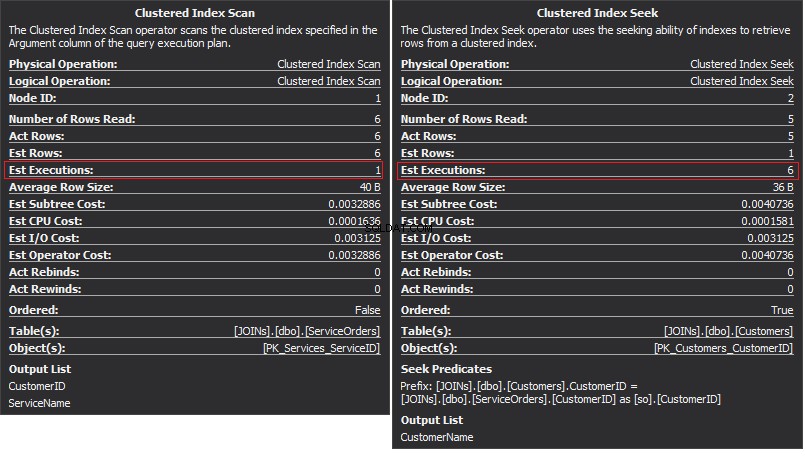
Parlons de la complexité. Supposons N est le numéro de ligne de la sortie externe. M est le nombre total de lignes dans les SalesOrders table. Ainsi, la complexité de la requête est O(NLogM) où LogM est la complexité de chaque recherche dans l'entrée interne. L'optimiseur sélectionnera cet opérateur chaque fois que l'entrée externe est petite et que l'entrée interne contient un index dans la colonne qui agit comme couture. Par conséquent, les index et les statistiques sont essentiels pour ce type JOIN, sinon SQL Server peut accidentellement penser qu'il n'y a pas autant de lignes dans l'une des entrées. Il est préférable d'effectuer une analyse de table plutôt que d'effectuer une recherche d'index 100 000 fois. Surtout lorsque la taille de l'entrée interne est supérieure à 100 Ko.
Résumé :
Boucles imbriquées
- Complexité :O(NlogM)
- S'applique généralement lorsqu'une table est petite
- La plus grande table contient un index qui permet de la rechercher à l'aide de la clé de jointure
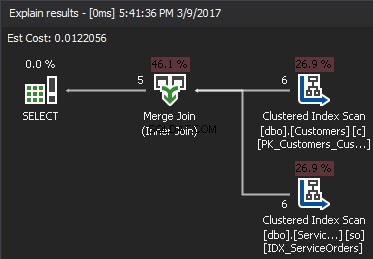
Fusionner la jointure
Certains développeurs ne comprennent pas complètement les JOIN de hachage et de fusion et les associent fréquemment à des requêtes peu performantes.
Contrairement à la boucle imbriquée qui accepte n'importe quel prédicat JOIN, la jointure de fusion nécessite au moins une jointure équi. De plus, les deux entrées doivent être triées sur les clés JOIN.
Le pseudo-code de l'algorithme MERGE JOIN :
L'algorithme compare deux entrées triées. Une rangée à la fois. Dans le cas où il y a une égalité entre deux lignes, les sorties de l'algorithme joignent les lignes et continuent. Si ce n'est pas le cas, l'algorithme ignore la moindre des deux entrées et continue. Contrairement à la boucle imbriquée, le coût ici est proportionnel à la somme du nombre de lignes d'entrée. En termes de complexité – O(N+M). Par conséquent, ce type de JOIN est souvent préférable pour les entrées volumineuses.
L'animation suivante montre comment l'algorithme MERGE JOIN joint les lignes de la table.
Résumé
- Complexité :O(N+M)
- Les deux entrées doivent être triées sur la clé de jointure
- Un opérateur d'égalité est utilisé
- Excellent pour les grandes tables
Hash Join
Hash Join est bien adapté aux grandes tables sans index utilisable. Lors de la première étape - phase de construction l'algorithme crée un index de hachage en mémoire sur l'entrée de gauche. La deuxième étape s'appelle la phase d'exploration . L'algorithme parcourt l'entrée de droite et trouve des correspondances à l'aide de l'index créé pendant la phase de construction. A vrai dire, ce n'est pas bon signe lorsque l'optimiseur choisit ce type d'algorithme JOIN.
Deux concepts importants sous-tendent ce type de JOIN :la fonction de hachage et la table de hachage.
Une fonction de hachage est toute fonction qui peut être utilisée pour mapper des données de taille variable à des données de taille fixe.
Une table de hachage est une structure de données utilisée pour implémenter un tableau associatif, une structure qui peut mapper des clés sur des valeurs. Une table de hachage utilise une fonction de hachage pour calculer un index dans un tableau de compartiments ou d'emplacements, à partir duquel la valeur souhaitée peut être trouvée.
En fonction des statistiques disponibles, SQL Server choisit la plus petite entrée comme entrée de génération et l'utilise pour créer une table de hachage en mémoire. S'il n'y a pas assez de mémoire, SQL Server utilise l'espace disque physique dans TempDB. Une fois la table de hachage créée, SQL Server obtient les données de l'entrée de la sonde (table plus grande) et les compare à la table de hachage à l'aide d'une fonction de correspondance de hachage. En conséquence, il renvoie les lignes correspondantes.
Si nous regardons le plan d'exécution, l'élément en haut à droite est l'entrée de construction , et l'élément en bas à droite est l'entrée de la sonde . Dans le cas où les deux entrées sont extrêmement volumineuses, le coût est trop élevé.
Pour estimer la complexité, supposez ce qui suit :
hc – complexité de la création de la table de hachage
hm – complexité de la fonction de correspondance de hachage
N – tableau plus petit
M – table plus grande
J – ajout de complexité pour le calcul dynamique et création de la fonction de hachage
La complexité sera :O(N*hc + M*hm + J)
L'optimiseur utilise des statistiques pour déterminer la cardinalité des valeurs. Ensuite, il crée dynamiquement une fonction de hachage qui divise les données en plusieurs compartiments de tailles égales. Il est souvent difficile d'estimer la complexité du processus de création de table de hachage, ainsi que la complexité de chaque correspondance de hachage en raison de la nature dynamique. Le plan d'exécution peut même afficher des estimations incorrectes car l'optimiseur effectue toutes ces opérations dynamiques pendant le temps d'exécution. Dans certains cas, le plan d'exécution peut montrer que Nested Loop est plus cher que Hash Join, mais en fait, Hash Join s'exécute plus lentement en raison d'une estimation de coût incorrecte.
Résumé
- Complexité :O(N*hc +M*hm +J)
- Type de jointure de dernier recours
- Utilise une table de hachage et une fonction de correspondance de hachage dynamique pour faire correspondre les lignes
Produits utiles :
SQL Complete – écrivez, embellissez, refactorisez votre code facilement et augmentez votre productivité.