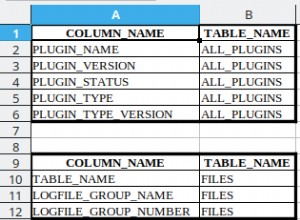
crosstab() fonction avec deux paramètres.
Cela devrait fonctionner comme ceci, pour obtenir des valeurs pour 2012 :
SELECT * FROM crosstab(
$$SELECT testname, to_char(last_update, 'mon_YYYY'), count(*)::int AS ct
FROM tests
WHERE current_status = 'FAILED'
AND last_update >= '2012-01-01 0:0'
AND last_update < '2013-01-01 0:0' -- proper date range!
GROUP BY 1,2
ORDER BY 1,2$$
,$$VALUES
('jan_2012'::text), ('feb_2012'), ('mar_2012')
, ('apr_2012'), ('may_2012'), ('jun_2012')
, ('jul_2012'), ('aug_2012'), ('sep_2012')
, ('oct_2012'), ('nov_2012'), ('dec_2012')$$)
AS ct (testname text
, jan_2012 int, feb_2012 int, mar_2012 int
, apr_2012 int, may_2012 int, jun_2012 int
, jul_2012 int, aug_2012 int, sep_2012 int
, oct_2012 int, nov_2012 int, dec_2012 int);
Trouvez une explication détaillée sous cette question connexe.
Je n'ai pas testé. Comme @Craig l'a commenté, des exemples de valeurs auraient aidé.
Testé maintenant avec mon propre cas de test.
Ne pas afficher les valeurs NULL
Le problème principal (que les mois sans lignes ne s'afficheraient pas du tout) est évité par le crosstab() fonction avec deux paramètres.
Vous ne pouvez pas utiliser COALESCE dans la requête interne, car le NULL les valeurs sont insérées par crosstab() lui-même. Vous pourriez ...
1. Enveloppez le tout dans une sous-requête :
SELECT testname
,COALESCE(jan_2012, 0) AS jan_2012
,COALESCE(feb_2012, 0) AS feb_2012
,COALESCE(mar_2012, 0) AS mar_2012
, ...
FROM (
-- query from above)
) x;
2. LEFT JOIN la requête principale à la liste complète des mois.
Dans ce cas, vous n'avez pas besoin du deuxième paramètre par définition.
Pour une plus grande plage, vous pouvez utiliser generate_series() pour créer les valeurs.
SELECT * FROM crosstab(
$$SELECT t.testname, m.mon, count(x.testname)::int AS ct
FROM (
VALUES
('jan_2012'::text), ('feb_2012'), ('mar_2012')
,('apr_2012'), ('may_2012'), ('jun_2012')
,('jul_2012'), ('aug_2012'), ('sep_2012')
,('oct_2012'), ('nov_2012'), ('dec_2012')
) m(mon)
CROSS JOIN (SELECT DISTINCT testname FROM tests) t
LEFT JOIN (
SELECT testname
,to_char(last_update, 'mon_YYYY') AS mon
FROM tests
WHERE current_status = 'FAILED'
AND last_update >= '2012-01-01 0:0'
AND last_update < '2013-01-01 0:0' -- proper date range!
) x USING (mon)
GROUP BY 1,2
ORDER BY 1,2$$
)
AS ct (testname text
, jan_2012 int, feb_2012 int, mar_2012 int
, apr_2012 int, may_2012 int, jun_2012 int
, jul_2012 int, aug_2012 int, sep_2012 int
, oct_2012 int, nov_2012 int, dec_2012 int);
Cas de test avec des exemples de données
Voici un cas de test avec quelques exemples de données que l'OP n'a pas réussi à fournir. Je l'ai utilisé pour le tester et le faire fonctionner.
CREATE TEMP TABLE tests (
id bigserial PRIMARY KEY
,testname text NOT NULL
,last_update timestamp without time zone NOT NULL DEFAULT now()
,current_status text NOT NULL
);
INSERT INTO tests (testname, last_update, current_status)
VALUES
('foo', '2012-12-05 21:01', 'FAILED')
,('foo', '2012-12-05 21:01', 'FAILED')
,('foo', '2012-11-05 21:01', 'FAILED')
,('bar', '2012-02-05 21:01', 'FAILED')
,('bar', '2012-02-05 21:01', 'FAILED')
,('bar', '2012-03-05 21:01', 'FAILED')
,('bar', '2012-04-05 21:01', 'FAILED')
,('bar', '2012-05-05 21:01', 'FAILED');