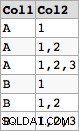
Construire sur votre original
Votre requête d'origine était sur la bonne voie pour exclure les lignes incriminées. Vous venez d'avoir > au lieu de = . Il manquait l'étape délicate pour compter.
SELECT count(*) AS ct
FROM (
SELECT 1
FROM compatibility c
WHERE rating_id = 1
AND NOT EXISTS (
SELECT 1
FROM compatibility c2
WHERE c2.rating_id > 1
AND (c2.attr1_id = c.attr1_id AND c2.attr2_id = c.attr2_id OR
c2.attr1_id = c.attr2_id AND c2.attr2_id = c.attr1_id))
GROUP BY least(attr1_id, attr2_id), greatest(attr1_id, attr2_id)
) sub;
Plus court
Probablement plus rapide aussi.
SELECT count(*) AS ct
FROM (
SELECT 1 -- selecting more columns for count only would be a waste
FROM compatibility
GROUP BY least(attr1_id, attr2_id), greatest(attr1_id, attr2_id)
HAVING every(rating_id = 1)
) sub;
Semblable à la requête de @Clodoaldo
ou cette réponse précédente avec plus d'explications
.every(rating_id = 1) est plus simple que not bool_or(rating_id > 1) , mais exclut également rating < 1 - ce qui est probablement bien (voire mieux) pour votre cas.
MySQL n'implémente pas actuellement (SQL standard !) every() . Puisque vous voulez seulement éliminer rating_id > 1 , cette expression simple correspond mieux à vos besoins et fonctionne dans les deux SGBDR :
HAVING max(rating_id) = 1
Le plus court
Avec count(*) en tant que fonction d'agrégation de fenêtre et sans sous-requête.
SELECT count(*) OVER () AS ct
FROM compatibility
GROUP BY least(attr1_id, attr2_id), greatest(attr1_id, attr2_id)
HAVING max(rating_id) = 1
LIMIT 1;
Les fonctions de fenêtre sont appliquées après l'étape globale. En nous appuyant sur cela, nous obtenons deux regrouper les étapes effectuées dans un seul niveau de requête :
- Plier l'équivalent
(atr1_id, atr2_id), à l'exclusion des lignes oùrating_iddivergent existent. - Compter les lignes restantes avec une fonction de fenêtre sur l'ensemble.
LIMIT 1 pour obtenir une seule ligne (toutes les lignes seraient identiques).
MySQL n'a pas de fonctions de fenêtre. Postgres uniquement.
Le plus court, pas nécessairement le plus rapide.
SQL Fiddle. (Sur pg9.2 puisque pg9.3 est actuellement hors ligne.)