CREATE TABLE test (id INT4 PRIMARY KEY, some_name TEXT, j json);
copy test FROM stdin;
01 TEST1 {"key1" : "value1", "key2": "value2", "key4": "value4"}
02 TEST1 {"key1" : "value1"}
03 TEST2 {"key1" : "value1", "key2": "value2", "key3":"value3"}
\.
with unpacked as (
SELECT (json_each_text(j)).* FROM test
)
SELECT value, count(*) FROM unpacked WHERE key in ('key1', 'key2', 'key3') group by value;
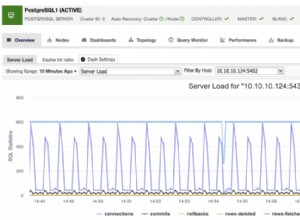
Renvoie :
value | count
--------+-------
value1 | 3
value3 | 1
value2 | 2
(3 rows)
Le renvoyer comme vous l'avez montré ne me semble pas une bonne idée (que voudriez-vous faire s'il y a 4 milliards de valeurs différentes ?), Mais vous pouvez toujours pivoter dans votre application ou modifier la requête pour effectuer le pivotement.