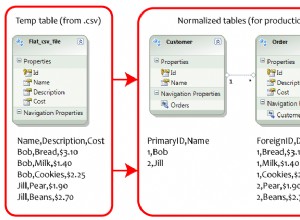
Cela devrait faire l'affaire :
SELECT a
, sum(ab_ct)::int AS ct_total
, count(*)::int AS ct_distinct_b
, array_agg(b || ', ' || ab_ct::text) AS b_arr
FROM (
SELECT a, b, count(*) AS ab_ct
FROM tbl
GROUP BY a, b
ORDER BY a, ab_ct DESC, b -- append "b" to break ties in the count
) t
GROUP BY a
ORDER BY ct_total DESC;
Renvoie :
ct_total:nombre total debpara.ct_distinct_b:nombre debdistincts para.b_arr:tableau debplus fréquence deb, triés par fréquence deb.
Trié par nombre total de b par a .
Alternativement, vous pouvez utiliser un ORDER BY clause dans l'appel agrégé
dans PostgreSQL 9.0 ou version ultérieure. Comme :
SELECT a
, sum(ab_ct)::int AS ct_total
, count(*)::int AS ct_distinct_b
, array_agg(b || ', ' || ab_ct::text ORDER BY a, ab_ct DESC, b) AS b_arr
FROM (
SELECT a, b, count(*) AS ab_ct
FROM tbl
GROUP BY a, b
) t
GROUP BY a
ORDER BY ct_total DESC;Peut être plus clair. Mais c'est généralement plus lent. Et le tri des lignes dans une sous-requête fonctionne pour des requêtes simples comme celle-ci. Plus d'explication :