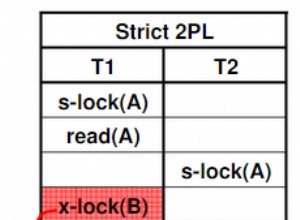
Vous rencontrez très probablement des conditions de concurrence . Lorsque vous exécutez votre fonction 1 000 fois en succession rapide dans des transactions distinctes , quelque chose comme ceci se produit :
T1 T2 T3 ...
SELECT max(id) -- id 1
SELECT max(id) -- id 1
SELECT max(id) -- id 1
...
Row id 1 locked, wait ...
Row id 1 locked, wait ...
UPDATE id 1
...
COMMIT
Wake up, UPDATE id 1 again!
COMMIT
Wake up, UPDATE id 1 again!
COMMIT
...
En grande partie réécrit et simplifié en tant que fonction SQL :
CREATE OR REPLACE FUNCTION get_result(val1 text, val2 text)
RETURNS text AS
$func$
UPDATE table t
SET id_used = 'Y'
, col1 = val1
, id_used_date = now()
FROM (
SELECT id
FROM table
WHERE id_used IS NULL
AND id_type = val2
ORDER BY id
LIMIT 1
FOR UPDATE -- lock to avoid race condition! see below ...
) t1
WHERE t.id_type = val2
-- AND t.id_used IS NULL -- repeat condition (not if row is locked)
AND t.id = t1.id
RETURNING id;
$func$ LANGUAGE sql;
Question connexe avec beaucoup plus d'explications :
Expliquez
-
N'exécutez pas deux instructions SQL distinctes. Cela coûte plus cher et élargit le délai pour les conditions de course. Une
UPDATEavec une sous-requête, c'est bien mieux. -
Vous n'avez pas besoin de PL/pgSQL pour la tâche simple. Vous pouvez toujours utiliser PL/pgSQL, la
UPDATEreste le même. -
Vous devez verrouiller la ligne sélectionnée pour vous défendre contre les conditions de concurrence. Mais vous ne pouvez pas le faire avec la fonction d'agrégation que vous dirigez car, par documentation :
-
Bold emphase mienne. Heureusement, vous pouvez remplacer
min(id)facilement avec l'équivalentORDER BY/LIMIT 1J'ai fourni ci-dessus. Peut tout aussi bien utiliser un index. -
Si la table est grande, vous avez besoin un index sur
idau moins. En supposant queidest déjà indexé en tant quePRIMARY KEY, Cela aiderait. Mais cet index multicolonne partiel supplémentaire aiderait probablement beaucoup plus :CREATE INDEX foo_idx ON table (id_type, id) WHERE id_used IS NULL;
Solutions alternatives
Verrous consultatifs Peut-être l'approche supérieure ici :
Ou vous voudrez peut-être verrouiller plusieurs lignes à la fois :