Dans nos précédents blogs sur le cloud hybride, nous mentionnons souvent que l'une des principales options pour profiter de la configuration de la topologie du cloud hybride est de l'utiliser comme cible de reprise après sinistre. Il est courant pour une structure organisationnelle qu'un plan de reprise après sinistre (DRP) soit toujours traité avant la mise en œuvre architecturale de la configuration de votre base de données, que ce soit dans le cloud ou sur site. Vous pourriez penser que tout échouera de manière imprévisible et peut affecter tragiquement votre entreprise s'il n'est pas traité et compris correctement. Surmonter ces défis nécessite un DRP (Disaster Recovery Plan) efficace, pour lequel votre système est bien configuré en fonction de votre application, de votre infrastructure et des exigences de votre entreprise. La clé du succès dans ces types de situations est la rapidité avec laquelle nous pouvons résoudre ou résoudre le problème.
Alors que le DRP traite les circonstances de la catastrophe, la continuité des activités s'assurera que le DRP est testé et opérationnel à tout moment si nécessaire. Vos options de reprise après sinistre pour vos bases de données doivent assurer un fonctionnement continu et limité aux limites des attentes. Il doit être conforme à votre RTO et RPO souhaités. Il est impératif de s'assurer que les bases de données de production sont disponibles pour les applications même en cas de sinistre; sinon, cela pourrait finir par être une affaire coûteuse. Les administrateurs de base de données, les architectes, doivent s'assurer que les environnements de base de données peuvent résister aux sinistres et sont conformes aux SLA de reprise après sinistre. Les déploiements de base de données doivent être configurés correctement pour garantir que les sinistres n'affectent pas la disponibilité de la base de données et la continuité des activités.
Options de reprise après sinistre
Votre cluster PostgreSQL doit être configuré avec une approche systématique qui respecte les meilleures pratiques et est acceptable par rapport aux normes de l'industrie. Parallèlement aux approches systématiques, les processus ou mécanismes suivants vous aident à vous assurer que votre PostgreSQL déployé sur un cloud hybride dispose de ces présences :
-
Basculement/Basculement
-
Sauvegarde automatisée
-
Haute disponibilité
-
Équilibrage de charge
-
Environnement hautement distribué
Basculement/Basculement
Le basculement est un processus automatisé en cas de défaillance de votre maître ; le serveur de secours à chaud ou de secours à chaud est promu au rôle de serveur principal/maître. C'est une bonne pratique qui permet à un environnement à haute disponibilité d'avoir au moins un nœud secondaire pour agir en tant que candidat pour un nœud de basculement. Une fois que le serveur principal tombe en panne, le serveur de secours doit commencer les procédures de basculement, puis le serveur secondaire ou de secours doit jouer le rôle de maître. Un système de basculement utilise un minimum de deux serveurs dans la pratique courante, qui servent de serveur principal et de secours. Sa vérification de la connectivité est assistée par un mécanisme de pulsation qui effectue des vérifications non-stop et vérifie si les deux sont en bon état et si la communication est active. Cependant, dans certains cas, la connectivité peut donner une fausse alerte. Par conséquent, dans certaines configurations et certains environnements, la présence d'un troisième système tel qu'un nœud de surveillance se trouve sur un réseau ou un centre de données distinct. Il s'agit d'une option infaillible pour empêcher un basculement inapproprié ou indésirable. Un nœud de vérification infaillible peut posséder des fonctionnalités et des contrôles supplémentaires, ce qui ajoute de la complexité. Cette configuration nécessite des tests complets et rigoureux pour s'assurer que le basculement est effectué correctement en cas de modification de l'implémentation. De plus, cela est important pour éviter toute détérioration de votre PostgreSQL
Supposons que votre cluster secondaire ou de secours se trouve dans un centre de données différent avec une configuration matérielle différente ; vous ne voudrez peut-être pas basculer brusquement, surtout si ce n'est pas un cas idéal à cause d'un simple faux positif. Cependant, dans ce scénario, votre nœud ou cluster cible de récupération de données doit disposer des mêmes ressources et spécifications que votre nœud ou cluster principal. Si votre cible de récupération de données se trouve dans un cloud public et que le principal est sur site, assurez-vous qu'il a déjà été couvert dans votre planification de capacité et que les ressources ont presque les mêmes spécifications pour éviter des résultats indésirables.
Lors de l'utilisation et de la préparation de votre mécanisme de basculement dans votre cluster PostgreSQL au sein d'un cloud hybride, vous devez vous assurer que votre outil est parfaitement adapté pour effectuer le travail censé accomplir. Il existe des outils tiers qui ne sont pas intégrés à PostgreSQL en ce qui concerne le basculement avancé. Par exemple, il y a ClusterControl, pg_auto_failover de CitusData (c/o Microsoft), Pgpool-II, Bucardo et autres. Ces outils utilitaires avancés fournissent une clôture de nœud ou connue sous le nom de STONITH (tirer sur l'autre nœud dans la tête). Cela garantit que votre nœud principal ou maître défaillant évitera d'accepter des écritures ou de revenir en ligne dans son état précédent pour servir des transactions normales. Ce problème est communément appelé scénario split-brain. Il perd la synchronisation des données en raison d'une panne (au niveau du matériel ou des ressources), mais vos serveurs principaux, qui sont censés n'être qu'un seul serveur principal, agissent comme s'ils faisaient des destinataires normaux de demandes d'écriture de données, provoquant une corruption des données à l'échelle du cluster.
Sauvegarde automatisée
Les sauvegardes offrent toujours une assurance élevée et des protections contre la perte de données. La sauvegarde maximise votre RPO car elle aide à minimiser la perte de données en cas de catastrophe. Les éléments que vous devez prendre en compte et préparer pour votre sauvegarde automatisée couvrent votre appareil/matériel de sauvegarde, la redondance des données de sauvegarde, la sécurité, les performances, la vitesse et le stockage des données.
Appareil de sauvegarde
Vous devez avoir ici le meilleur choix pour votre appliance de sauvegarde. Vitesse, volume de stockage important et haute disponibilité peuvent être votre choix souhaité. Certains s'appuient sur le stockage SAN ou NAS ou distribuent leurs données à d'autres fournisseurs de stockage de sauvegarde tiers. Il est essentiel que votre appliance de sauvegarde offre une vitesse d'écriture et de lecture des données, en particulier si vous appliquez la compression et le chiffrement pour vos données au repos. La décompression et le déchiffrement nécessitent des ressources, vous devez donc déterminer quand vous devez utiliser la récupération de données. Au cours de cet état, vous devez déterminer que vous devez atteindre votre RPO maximal et engager le SLA (Service-Level Agreement) réalisable envers vos clients. Il est également idéal que vous deviez isoler votre sauvegarde de votre réseau local ou la stocker dans un emplacement distant. Une approche alternative consiste à s'engager avec des fournisseurs tiers. Par exemple, stocker votre sauvegarde dans le cloud peut être une option, et leur installation est très sophistiquée et répond à vos exigences.
Redondance des données de sauvegarde
La diffusion de vos données à plusieurs endroits est une solution idéale. Cela renforce vos chances de récupération de données, par exemple, une erreur humaine ou une erreur de logique logicielle vous obligeant à supprimer les anciennes copies de sauvegarde mais supprimant par erreur toutes les copies de sauvegarde cruciales. Dans certains environnements sophistiqués, tels que le stockage dans un environnement cloud tel qu'Amazon S3, Cloud Storage de Google ou Azure Blob Storage offre la réplication de votre fichier stocké. Cela offre plus de redondance et peut être configuré de manière flexible en fonction de vos besoins.
Haute disponibilité
Un cluster PostgreSQL hautement disponible dans un cloud hybride garantit toujours que la communication de votre base de données garantit la disponibilité. Le cas idéal de haute disponibilité dépend de la mesure de votre disponibilité. Dans ce cas, une configuration courante pour un PostgreSQL déployé dans un cloud hybride peut être soit votre base de données hébergée dans un cloud public, soit votre cluster secondaire agissant en tant que cluster de récupération de données au cas où le cluster principal tomberait en panne ou subirait un sinistre réseau et pourrait prendre beaucoup de temps d'arrêt. Dans certaines configurations, il est possible que le cluster secondaire situé dans le cloud public ne soit pas exactement aussi sophistiqué que le principal, disons qu'il s'agit de votre cloud sur site ou privé. Votre application peut jouer pour limiter les visiteurs ou le trafic pouvant se connecter à votre base de données. Ce type de scénario peut réduire vos coûts d'installation, mais bien sûr, cela ne dépend que de vos besoins. Si votre type d'application est volumineux et doit recevoir en permanence des situations de trafic normal à intense, assurez-vous que les ressources de votre cluster secondaire doivent être aussi puissantes que le principal pour garantir une haute disponibilité, c'est-à-dire 99,9999999 %.
Pour obtenir un cluster PostgreSQL hautement disponible dans un environnement cloud hybride, vous devez disposer d'un mécanisme de basculement. En cas de panne et de panne d'un cluster principal ou d'un serveur principal, un serveur secondaire ou de secours peut alors jouer le rôle de maître, quel que soit son emplacement. La chose la plus importante est la fonctionnalité, et les performances, en particulier du point de vue de l'application ou du client, ne sont pas du tout affectées ou du moins très minimes.
Équilibrage de charge
Le mécanisme d'équilibrage de charge pour votre cluster PostgreSQL facilite la configuration de votre cloud hybride, qui est plus gérable et moins risqué, en particulier en cas de charge de trafic élevée. Dans de nombreuses situations, un serveur reçoit une charge élevée et sévère, provoquant la panique du serveur. Cela conduit à un état inutilisable du serveur en raison de ressources occupées consommées par un grand nombre de threads exécutés en arrière-plan. Cette situation peut être améliorée en corrigeant les mauvaises requêtes et l'architecture de conception de votre base de données. Cela devrait inclure la façon dont vous répartissez la charge de lecture par rapport à l'écriture et une compréhension approfondie des exigences de votre application, comme la configuration maître-maître ou un seul maître, mais en le mettant à l'échelle verticalement pour fournir des ressources de calcul et de mémoire plus élevées. Il existe également une grande sélection d'outils tiers tels que pgbouncer et Pgpool II pour faciliter votre déploiement PostgreSQL dans un environnement de cloud hybride.
Environnement hautement distribué
Sur le plan de l'évolutivité, le fait d'être hautement distribué dans plusieurs emplacements ou différents fournisseurs de cloud (sur site ou cloud privé et public) offre plus de flexibilité et de tolérabilité dans un environnement de cloud hybride, ce qui est idéal pour la reprise après sinistre. Il est flexible lorsqu'il doit basculer sur un emplacement cloud particulier propice à une catastrophe naturelle ou à une catastrophe, en particulier si votre région désignée où réside votre cluster principal est actuellement dévastée ou affectée par une cause naturelle. C'est une cause inévitable que vous devez comprendre et être fiable de la situation actuelle. Votre application et vos clients doivent être servis en continu et sans interruption. Cela a pour but d'être disponible publiquement dans le cloud tout en servant également dans un environnement privé ou sur site. Cette configuration ajoute une plus grande complexité et nécessite des connaissances avancées du côté de la base de données, de la sécurité et de la mise en réseau. L'optimisation et le réglage sont cruciaux pour réussir ici, car il est très important que, tout en assurant une sécurité renforcée pour encapsuler vos données lors de vos déplacements sur Internet, il soit prouvé que les performances se stabilisent et ne sont pas affectées par la configuration mise en œuvre.
En raison de la complexité de la configuration, disposer d'un outil est idéal pour gérer le déploiement et faciliter l'état global de vos bases de données, en supervisant un aspect de votre cluster mais à l'ensemble du niveau depuis le cloud privé sur site, et sur l'aspect cloud public. Toutes les configurations doivent être maintenues à un niveau gérable et simple afin qu'en cas d'alarmes et d'alertes, il soit facile de corriger et de résoudre le problème correctement et en temps opportun.
ClusterControl pour la reprise après sinistre dans un environnement cloud hybride
ClusterControl permet à l'organisation ou aux entreprises de gérer la base de données avec flexibilité et de réduire la complexité globale de la configuration. ClusterControl offre un basculement, une sauvegarde automatisée, fournit une configuration hautement disponible, un équilibrage de charge et prend en charge un déploiement d'environnement distribué, ce qui facilite l'ajout de nœuds dans un cloud public, privé ou sur site.
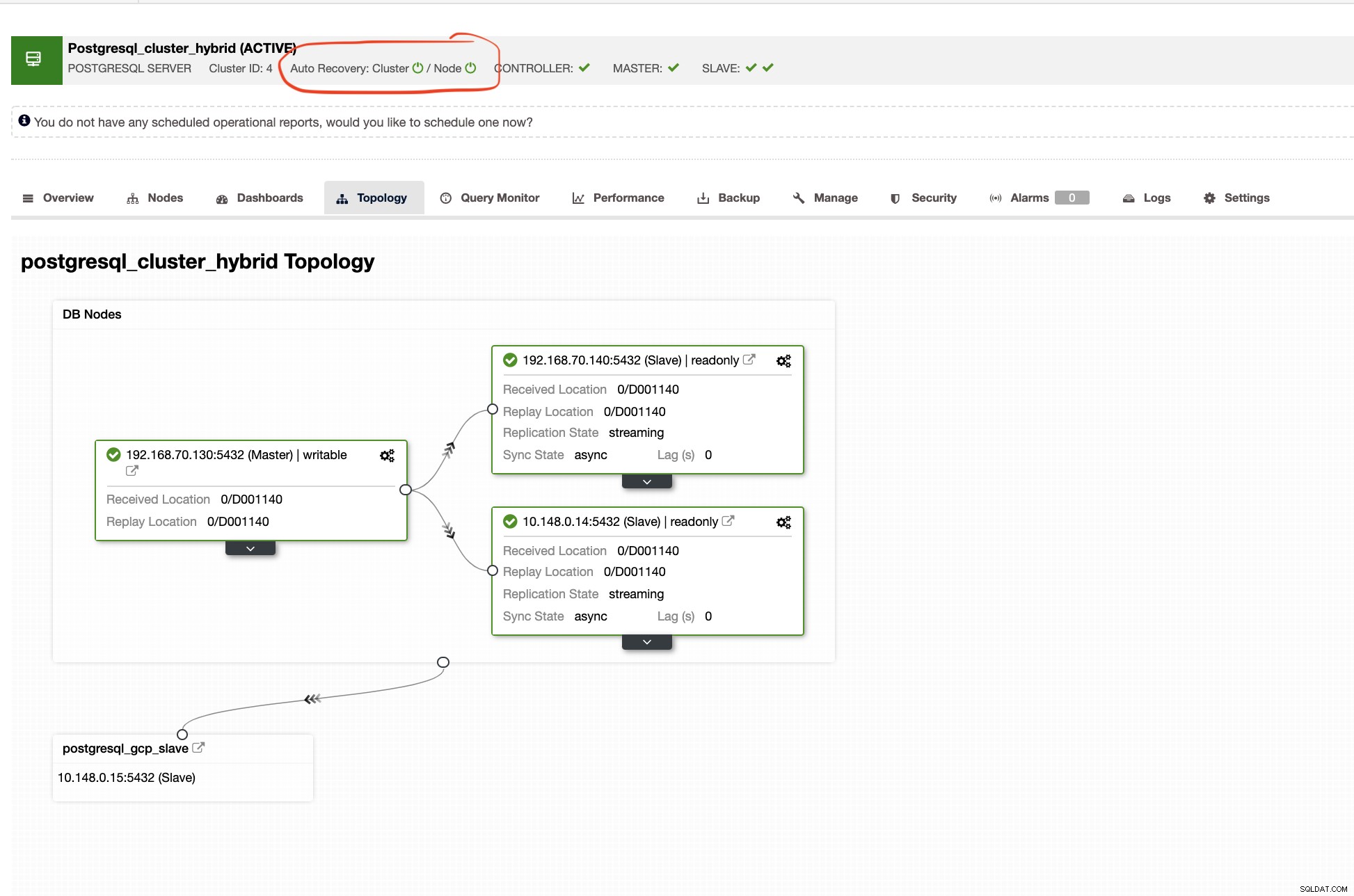
Récupération automatique de ClusterControl
La récupération automatique de ClusterControl représente des tonnes de mécanismes de basculement et de caractéristiques de récupération, en particulier lorsqu'un nœud tombe en panne ou qu'un cluster passe dans un état dégradé. Cela peut être facilement fait comme indiqué dans la capture d'écran ci-dessous :
Sauvegarde et restauration
ClusterControl dispose également d'une fonctionnalité de sauvegarde et de restauration qui vous permet de gérer votre sauvegarde, de créer une sauvegarde, de planifier une sauvegarde et de restaurer une sauvegarde. La gestion de votre sauvegarde est très simple et la création ou la planification d'une sauvegarde est simple mais offre également des options avancées. Il offre également des options de sauvegarde dans le cloud qui vous permettent d'avoir une redondance des données de sauvegarde, renforçant ainsi vos options de reprise après sinistre. Voir ci-dessous :
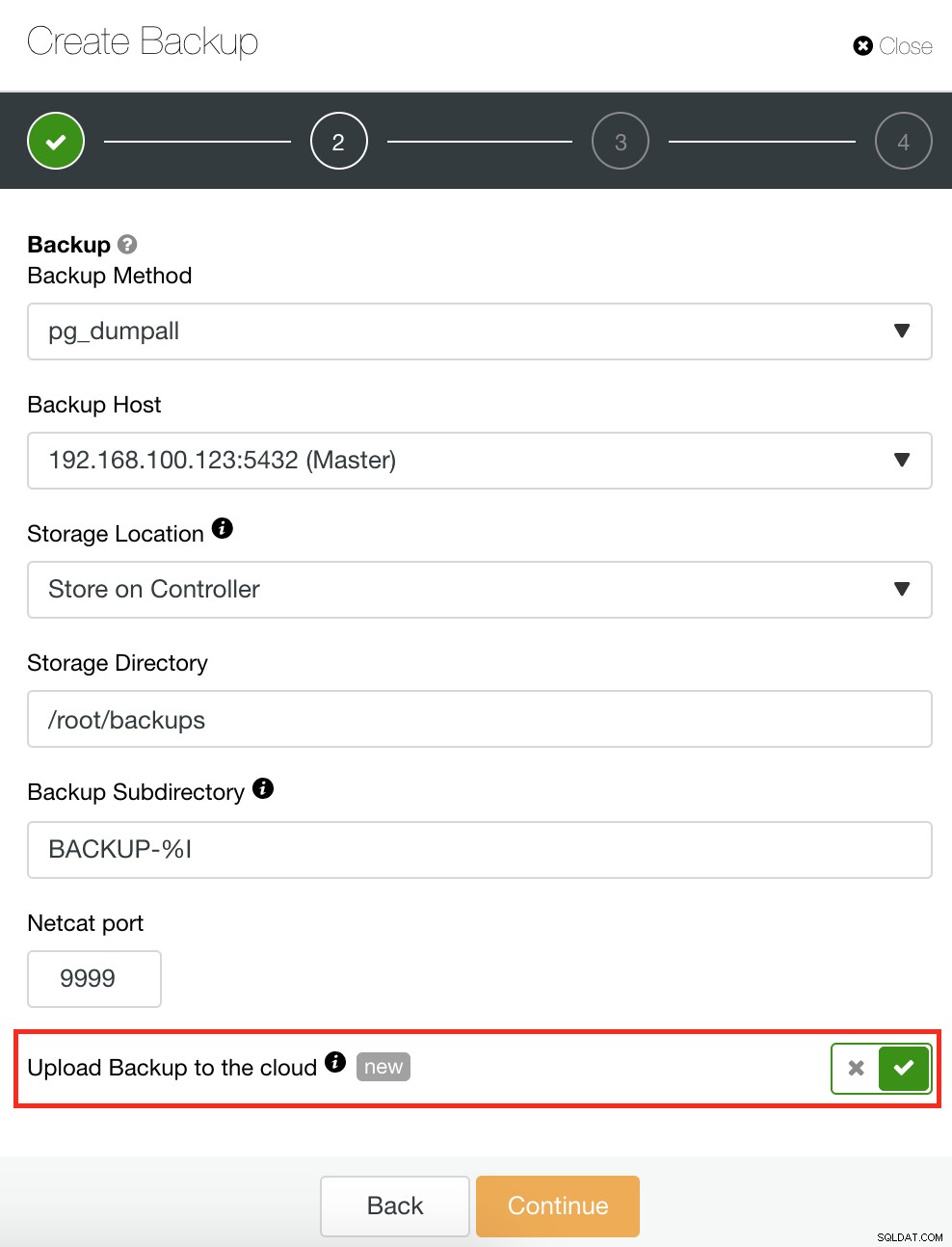
Comme indiqué ci-dessous, la gestion de votre sauvegarde fournit une interface utilisateur simple vous permettant de sélectionner la sauvegarde que vous souhaitez restaurer, sinon vous devrez peut-être la supprimer. La sauvegarde de ClusterControl vous permet de choisir une période de rétention, donc si vous avez une longue liste, certaines d'entre elles peuvent être supprimées lorsqu'elle atteint sa période de rétention. 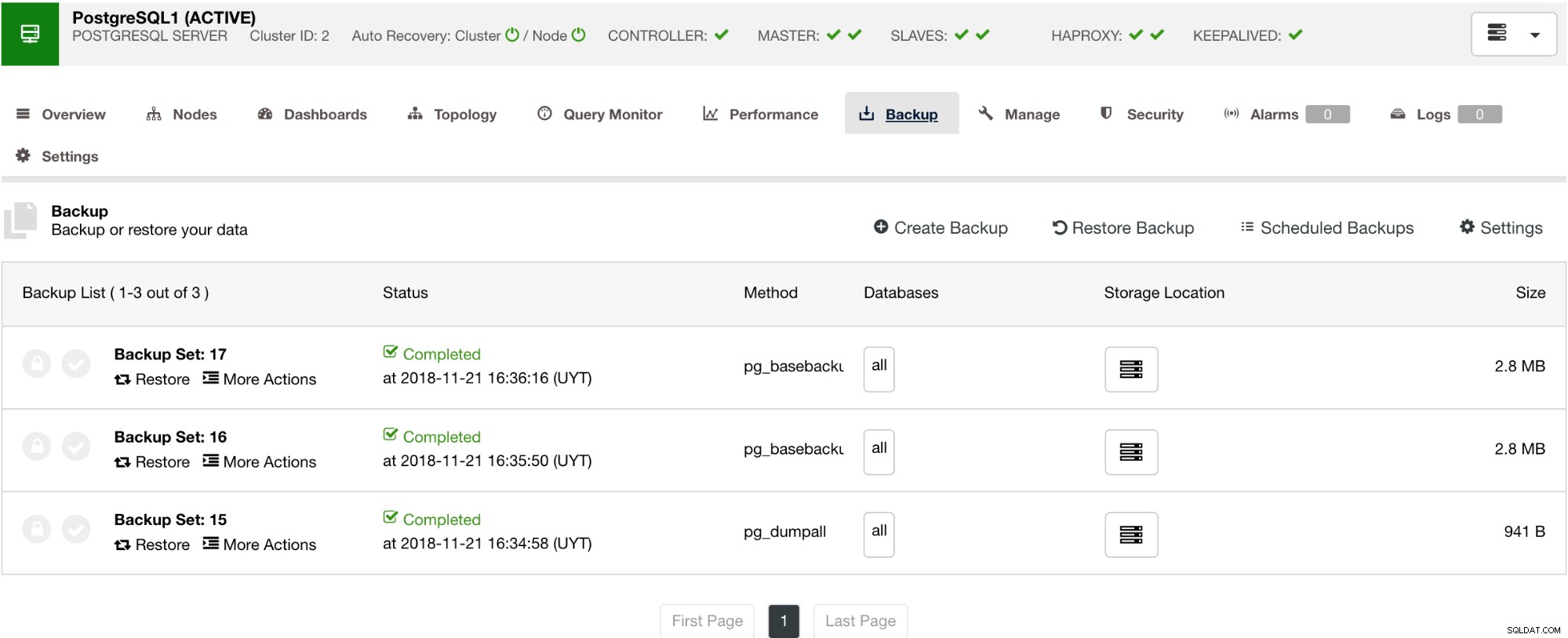
Prend en charge les mécanismes de haute disponibilité (HA) et d'équilibrage de charge (LB)
Vous n'avez pas besoin de configurer manuellement ni même de rechercher des moyens d'ajouter une haute disponibilité dans votre cluster PostgreSQL. Il existe un moyen simple et pratique de faire le travail avec ClusterControl. Si vous pouvez voir l'exemple de capture d'écran, il a une configuration HAProxy et Keepalived. Voir capture d'écran ci-dessous :
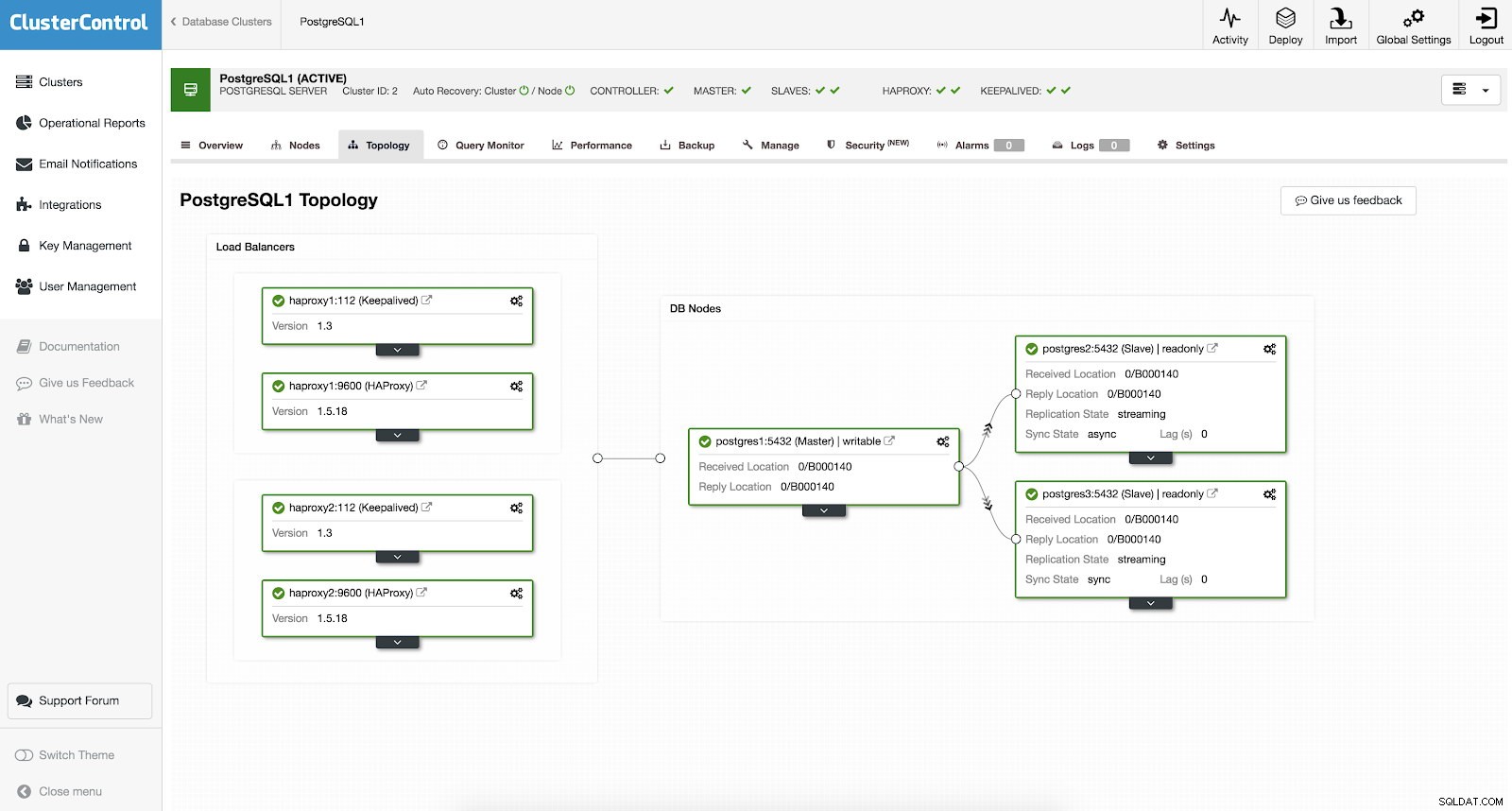
La configuration d'une haute disponibilité avec ClusterControl peut être effectuée en accédant à
Prend en charge l'environnement distribué
Si vous souhaitez avoir des distributions uniformes du cloud sur site ou privé au cloud public, ClusterControl prend également en charge le déploiement du cloud. Mais pour un cluster PostgreSQL et que vous prévoyez d'avoir un esclave secondaire résidant sur un autre cloud, vous pouvez créer un cluster esclave comme indiqué ci-dessous,
et vous pouvez arriver avec le résultat final comme indiqué ci-dessous,

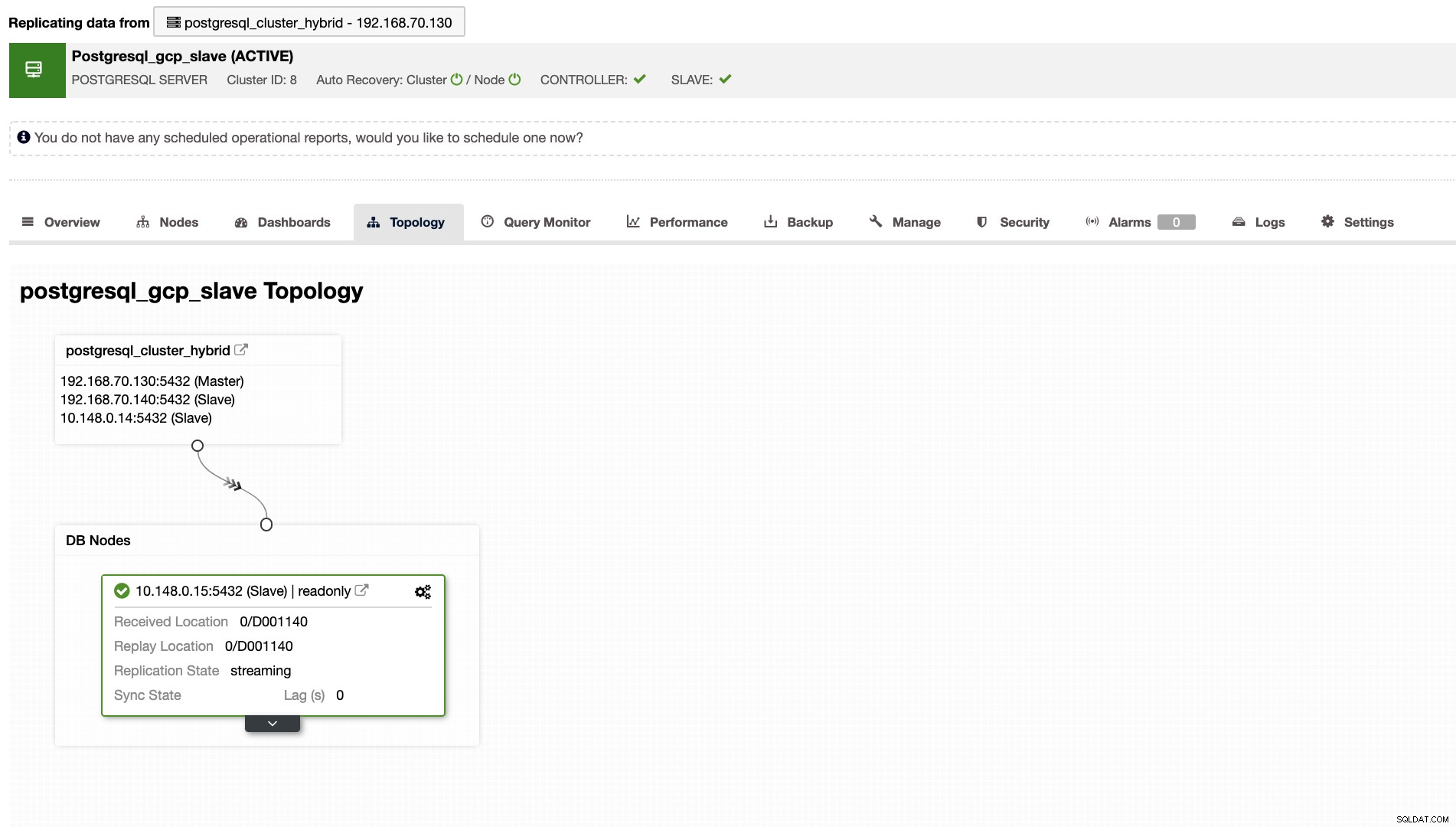
ClusterControl vous montrera également la bonne topologie de votre cluster chaque fois que vous avez configuré un environnement de cloud hybride. Voir ci-dessous,
Alors que dans le cluster esclave, la topologie montrera son arbre d'origine révélant son maître. L'esclave ici s'affiche dans la mesure où il se trouve dans un réseau distinct situé principalement dans Google Cloud, tandis que le maître est sur site.
Conclusion
Il est acceptable d'admettre qu'une configuration de cloud hybride, en particulier avec un cluster PostgreSQL, ajoute de la complexité. Vous devez disposer du bon outil avec des options présentes pour prendre en charge votre planification de reprise après sinistre. Celles-ci sont très importantes pour sauver et éviter à votre entreprise la catastrophe potentielle des dommages financiers et la perte de la confiance des clients. Investissez dans les bons outils et compétences de votre technologie, et vous éviterez à votre entreprise un impact négatif.