La gestion de la mémoire dans PostgreSQL est importante pour améliorer les performances du serveur de base de données. Le fichier de configuration PostgreSQL (postgres.conf) gère la configuration du serveur de base de données. Il utilise les valeurs par défaut des paramètres, mais nous pouvons modifier ces valeurs pour mieux refléter la charge de travail et l'environnement d'exploitation.
Dans ce blog, nous couvrirons ces paramètres liés à la mémoire. Mais avant de commencer, regardons l'architecture de la mémoire dans PostgreSQL.
Architecture de la mémoire
La mémoire dans PostgreSQL peut être classée en deux catégories :
- Zone de mémoire locale :elle est allouée par chaque processus backend pour son propre usage.
- Zone de mémoire partagée :elle est utilisée par tous les processus d'un serveur PostgreSQL.
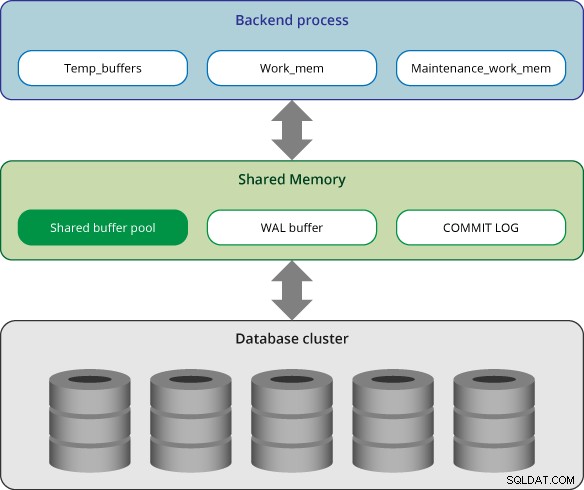
Zone de mémoire locale
Dans PostgreSQL, chaque processus backend alloue de la mémoire locale pour le traitement des requêtes ; chaque zone est divisée en sous-zones dont les tailles sont fixes ou variables.
Les sous-domaines sont les suivants.
Work_mem
L'exécuteur utilise cette zone pour trier les tuples par les opérations ORDER BY et DISTINCT. Il l'utilise également pour joindre des tables par des opérations de fusion-jointure et de hachage-jointure.
Maintenance_work_mem
Ce paramètre est utilisé pour certains types d'opérations de maintenance (VACUUM, REINDEX).
Temp_buffers
L'exécuteur utilise cette zone pour stocker les tables temporaires.
Zone de mémoire partagée
La zone de mémoire partagée est allouée par le serveur PostgreSQL lors de son démarrage. Cette zone est divisée en plusieurs sous-zones de taille fixe.
Pool de mémoire tampon partagé
PostgreSQL charge les pages des tables et des index depuis le stockage persistant vers un pool de mémoire tampon partagé, puis les exécute directement.
Tampon WAL
PostgreSQL prend en charge le mécanisme WAL (Write ahead log) pour s'assurer qu'aucune donnée n'est perdue après une panne de serveur. Les données WAL sont vraiment un journal de transactions dans PostgreSQL et le tampon WAL est une zone de mise en mémoire tampon des données WAL avant de les écrire dans un stockage persistant.
Journal de validation
Le journal de validation (CLOG) conserve les états de toutes les transactions et fait partie du mécanisme de contrôle de la concurrence. Le journal de validation est alloué à la mémoire partagée et utilisé tout au long du traitement des transactions.
PostgreSQL définit les quatre états de transaction suivants.
- EN_COURS
- ENGAGÉ
- ANNULÉ
- SOUS-COMMIS
Réglage des paramètres de mémoire PostgreSQL
Certains paramètres importants sont recommandés pour la gestion de la mémoire dans PostgreSQL. Vous devez tenir compte des éléments suivants.
Tampons_partagés
Ce paramètre désigne la quantité de mémoire utilisée pour les tampons de mémoire partagée. Le paramètre shared_buffers détermine la quantité de mémoire dédiée au serveur pour la mise en cache des données. La valeur par défaut de shared_buffers est généralement de 128 mégaoctets (128 Mo).
La valeur par défaut de ce paramètre est très faible car sur certaines plates-formes comme les anciennes versions de Solaris et SGI, avoir des valeurs élevées nécessite une action invasive comme la recompilation du noyau. Même sur les systèmes Linux modernes, le noyau n'autorisera probablement pas la définition de shared_buffers à plus de 32 Mo sans ajuster d'abord les paramètres du noyau.
Le mécanisme a changé dans PostgreSQL 9.4 et versions ultérieures, de sorte que les paramètres du noyau n'auront pas à y être ajustés.
S'il y a une charge élevée sur le serveur de base de données, la définition d'une valeur élevée améliorera les performances.
Si vous disposez d'un serveur de base de données dédié avec 1 Go ou plus de RAM, une valeur de départ raisonnable pour le paramètre de configuration shared_buffer est de 25 % de la mémoire de votre système.
Valeur par défaut de shared_buffers =128 Mo. La modification nécessite le redémarrage du serveur PostgreSQL.
La recommandation générale pour définir les shared_buffers est la suivante.
- En dessous de 2 Go de mémoire, définissez la valeur de shared_buffers sur 20 % de la mémoire système totale.
- En dessous de 32 Go de mémoire, définissez la valeur de shared_buffers sur 25 % de la mémoire système totale.
- Au-delà de 32 Go de mémoire, définissez la valeur de shared_buffers sur 8 Go
Travail_mem
Ce paramètre spécifie la quantité de mémoire à utiliser par les opérations de tri internes et les tables de hachage avant d'écrire dans les fichiers de disque temporaires. Si de nombreux tris complexes se produisent et que vous disposez de suffisamment de mémoire, l'augmentation du paramètre work_mem permet à PostgreSQL d'effectuer des tris en mémoire plus volumineux, ce qui sera plus rapide que les équivalents basés sur disque.
Notez que pour une requête complexe, de nombreuses opérations de tri ou de hachage peuvent s'exécuter en parallèle. Chaque opération sera autorisée à utiliser autant de mémoire que cette valeur spécifie avant de commencer à écrire des données dans les fichiers temporaires. Il est possible que plusieurs sessions effectuent de telles opérations simultanément. Par conséquent, la mémoire totale utilisée peut être plusieurs fois supérieure à la valeur du paramètre work_mem.
N'oubliez pas que lorsque vous choisissez la bonne valeur. Les opérations de tri sont utilisées pour ORDER BY, DISTINCT et les jointures de fusion. Les tables de hachage sont utilisées dans les jointures par hachage, le traitement basé sur le hachage des sous-requêtes IN et l'agrégation basée sur le hachage.
Le paramètre log_temp_files peut être utilisé pour consigner les tris, les hachages et les fichiers temporaires, ce qui peut être utile pour déterminer si les tris se répandent sur le disque au lieu de tenir en mémoire. Vous pouvez vérifier les tris déversés sur le disque à l'aide des plans EXPLAIN ANALYZE. Par exemple, dans la sortie d'EXPLAIN ANALYZE, si vous voyez la ligne suivante :"Sort Method :external merge Disk :7528kB ", un work_mem d'au moins 8 Mo conserverait les données intermédiaires en mémoire et améliorerait le temps de réponse aux requêtes.
La valeur par défaut de work_mem =4 Mo.
La recommandation générale pour définir le work_mem est la suivante.
- Commencez avec une valeur faible :32 à 64 Mo
- Recherchez ensuite les lignes de "fichier temporaire" dans les journaux
- Réglé sur 2 à 3 fois le plus grand fichier temporaire
maintenance _work_mem
Ce paramètre spécifie la quantité maximale de mémoire utilisée par les opérations de maintenance telles que VACUUM, CREATE INDEX et ALTER TABLE ADD FOREIGN KEY. Étant donné qu'une seule de ces opérations peut être exécutée à la fois par une session de base de données et qu'une installation PostgreSQL n'en a pas beaucoup en cours d'exécution simultanément, il est prudent de définir la valeur de maintenance_work_mem de manière significative plus grande que work_mem.
La définition d'une valeur plus élevée peut améliorer les performances de nettoyage et de restauration des vidages de base de données.
Il est nécessaire de se rappeler que lorsque autovacuum s'exécute, jusqu'à autovacuum_max_workers fois cette mémoire peut être allouée, veillez donc à ne pas définir la valeur par défaut trop élevée.
La valeur par défaut de maintenance_work_mem =64 Mo.
La recommandation générale pour définir maintenance_work_mem est la suivante.
- Définissez la valeur 10 % de la mémoire système, jusqu'à 1 Go
- Vous pouvez peut-être le régler encore plus haut si vous rencontrez des problèmes de VACUUM
Effective_cache_size
effective_cache_size doit être définie sur une estimation de la quantité de mémoire disponible pour la mise en cache du disque par le système d'exploitation et dans la base de données elle-même. Il s'agit d'une indication de la quantité de mémoire que vous pensez être disponible dans le système d'exploitation et les caches de tampon PostgreSQL, et non d'une allocation.
Le planificateur de requêtes PostgreSQL utilise cette valeur pour déterminer si les plans qu'il envisage devraient tenir dans la RAM ou non. S'il est défini trop bas, les index peuvent ne pas être utilisés pour exécuter les requêtes comme prévu. Comme la plupart des systèmes Unix sont assez agressifs lors de la mise en cache, au moins 50 % de la RAM disponible sur un serveur de base de données dédié sera pleine de données mises en cache.
La recommandation générale pour effective_cache_size est la suivante.
- Définissez la valeur sur la quantité de cache du système de fichiers disponible
- Si vous ne savez pas, définissez la valeur sur 50 % de la mémoire système totale
La valeur par défaut de effective_cache_size =4 Go.
Temp_buffers
Ce paramètre définit le nombre maximal de tampons temporaires utilisés par chaque session de base de données. Les tampons locaux de session sont utilisés uniquement pour l'accès aux tables temporaires. Le réglage de ce paramètre peut être modifié au sein de sessions individuelles, mais uniquement avant la première utilisation des tables temporaires au sein de la session.
La base de données PostgreSQL utilise cette zone mémoire pour contenir les tables temporaires de chaque session, celles-ci seront effacées lorsque la connexion sera fermée.
La valeur par défaut de temp_buffer =8 Mo.
Conclusion
Comprendre l'architecture de la mémoire et régler les paramètres appropriés est important pour améliorer les performances. Ceci est particulièrement nécessaire pour les systèmes à charge de travail élevée. Pour des conseils de réglage des performances plus génériques, veuillez consulter cet aide-mémoire sur les performances pour PostgreSQL.



