Découvrez l'architecture d'ingestion de données en temps quasi réel pour transformer et enrichir les flux de données à l'aide d'Apache Flume, Apache Kafka et RocksDB à Santander UK.
Cloudera Professional Services a travaillé avec Santander UK pour créer un système d'analyse transactionnelle en temps quasi réel (NRT) sur Apache Hadoop. L'objectif est de capturer, transformer, enrichir, comptabiliser et stocker une transaction quelques secondes après un achat par carte. Le système reçoit les transactions par carte des clients de détail de la banque et calcule les informations de tendance associées agrégées par titulaire de compte et sur un certain nombre de dimensions et de taxonomies. Ces informations sont ensuite envoyées en toute sécurité à l'application "Spendlytics" de Santander (voir ci-dessous) pour permettre aux clients d'analyser leurs derniers modèles de dépenses.
Apache HBase a été choisi comme solution de stockage sous-jacente en raison de sa capacité à prendre en charge les écritures aléatoires à haut débit et les lectures aléatoires à faible latence. Cependant, l'exigence NRT excluait l'exécution de transformations et d'enrichissement des transactions par lots, elles doivent donc être effectuées pendant que les transactions sont diffusées dans HBase. Cela inclut la transformation des messages XML vers Avro et leur enrichissement avec des informations sur les tendances, telles que des informations sur la marque et le marchand.
Cet article décrit comment Santander utilise Apache Flume, Apache Kafka et RocksDB pour transformer, enrichir et diffuser des transactions dans HBase. Il s'agit d'une implémentation du NRT Event Processing with External Context modèle de diffusion décrit par Ted Malaska dans cet article.
Flafka
La première décision que Santander a dû prendre était de savoir comment diffuser au mieux les données dans HBase. Flume est presque toujours le meilleur choix pour l'ingestion de flux dans Hadoop compte tenu de sa simplicité, de sa fiabilité, de sa riche gamme de sources et de puits et de son évolutivité inhérente.
Récemment, une excellente intégration à Kafka a été ajoutée, menant à l'inévitable Flafka. Flume peut nativement fournir une livraison d'événements garantie via son canal de fichiers, mais la possibilité de rejouer les événements et la flexibilité supplémentaire et la pérennité apportées par Kafka ont été les principaux moteurs de l'intégration.
Dans cette architecture, Santander utilise les canaux Kafka pour fournir un tampon d'ingestion fiable, auto-équilibré et évolutif dans lequel toutes les transformations et tous les traitements sont représentés dans des rubriques Kafka chaînées. En particulier, nous utilisons largement la source et le puits de Flafka, et la capacité de Flume à effectuer un traitement en vol à l'aide d'intercepteurs. Cela nous a évité d'avoir à coder notre propre producteur et consommateur Kafka, et a permis à Santander de tirer pleinement parti de Cloudera Manager pour configurer, déployer et surveiller les agents et les courtiers.
Transformation
Les transactions capturées par les systèmes bancaires centraux sont transmises à Flume sous forme de messages XML, après avoir été lues à partir de la base de données source via la réplication des journaux. (Associer un journal de base de données aux sujets Kafka de cette manière est un modèle de plus en plus courant et, combiné au compactage des journaux, peut donner une "vue la plus récente" de la base de données pour les cas d'utilisation de capture de données modifiées.)
Flume stocke ces messages XML dans un sujet Kafka "brut". À partir de là, et en tant que précurseur de tous les autres traitements, il a été décidé de transformer le XML semi-structuré en enregistrements binaires structurés pour faciliter le traitement normalisé en aval. Ce traitement est effectué par un Flume Interceptor personnalisé qui transforme les messages XML en une représentation Avro générique, en appliquant des types spécifiques le cas échéant et en revenant à une représentation sous forme de chaîne dans le cas contraire. Tous les traitements NRT ultérieurs stockent ensuite les résultats dérivés dans Avro dans des rubriques Kafka dédiées, ce qui facilite l'accès au flux et l'obtention d'un flux d'événements à tout moment de la chaîne de traitement.
Si un traitement d'événements plus complexe était requis, par exemple des agrégations avec Spark Streaming, il serait trivial de consommer un ou plusieurs de ces sujets et de publier sur de nouveaux sujets dérivés. (Apache Avro est un choix naturel pour ce format :il s'agit d'un protocole binaire compact qui prend en charge l'évolution du schéma, possède une définition de schéma flexible et est pris en charge dans toute la pile Hadoop. Avro devient rapidement une norme de facto pour le stockage de données provisoire et général dans un hub de données d'entreprise et est parfaitement placé pour être transformé en Apache Parquet pour les charges de travail d'analyse.)
Enrichissement
L'inspiration pour la conception de la solution d'enrichissement en streaming est venue d'un article de O'Reilly Radar écrit par Jay Kreps. Dans son article, Jay décrit les avantages de l'utilisation d'un magasin local pour permettre à un processeur de flux d'interroger ou de modifier un état local en réponse à son entrée, par opposition aux appels à distance vers une base de données distribuée.
Chez Santander, nous avons adapté ce modèle pour fournir des magasins de référence locaux qui sont utilisés pour interroger et enrichir les transactions au fur et à mesure qu'elles transitent par Flume. Pourquoi ne pas simplement utiliser HBase comme magasin de référence ? Eh bien, un modèle typique pour ce type de problème consiste simplement à stocker l'état dans HBase et à demander au mécanisme d'enrichissement de l'interroger directement. Nous avons décidé de ne pas adopter cette approche pour plusieurs raisons. Premièrement, les données de référence sont relativement petites et s'intégreraient dans une seule région HBase, provoquant probablement un hotspot de région. Deuxièmement, HBase sert l'application Spendlytics orientée client et Santander ne voulait pas que la charge supplémentaire affecte la latence de l'application, ou vice versa. C'est aussi la raison pour laquelle nous avons décidé de ne pas utiliser HBase pour démarrer même les magasins locaux au démarrage.
Ainsi, en fournissant à chaque agent Flume un magasin local rapide pour enrichir les événements en vol, Santander est en mesure de donner de meilleures garanties de performance pour l'enrichissement en vol et l'application Spendlytics. Nous avons décidé d'utiliser RocksDB pour implémenter les magasins locaux car il est capable de fournir un accès rapide à de grandes quantités de données hors tas (éliminant ainsi la charge sur GC), et le fait qu'il dispose d'une API Java pour faciliter son utilisation à partir de un intercepteur de canal personnalisé. Cette approche nous a évité d'avoir à coder notre propre magasin hors tas. RocksDB peut facilement être remplacé par une autre implémentation de magasin local, mais dans ce cas, il convenait parfaitement au cas d'utilisation de Santander.
L'implémentation personnalisée de l'intercepteur d'enrichissement Flume traite les événements du sujet "transformé" en amont, interroge son magasin local pour les enrichir et écrit les résultats dans les sujets Kafka en aval en fonction du résultat. Ce processus est illustré plus en détail ci-dessous.
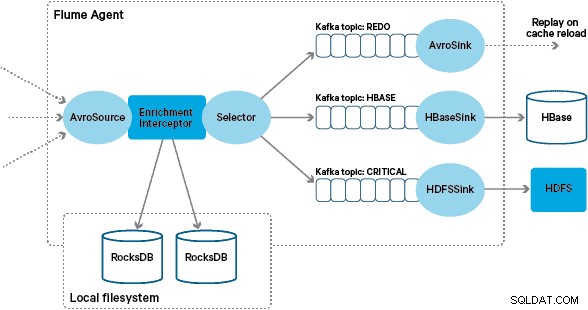
À ce stade, vous vous demandez peut-être :en l'absence de persistance fournie par HBase, comment les magasins locaux sont-ils générés ? Les données de référence comprennent un certain nombre d'ensembles de données différents qui doivent être réunis. Ces ensembles de données sont actualisés quotidiennement dans HDFS et constituent l'entrée d'une application Apache Spark planifiée, qui génère les magasins RocksDB. Les magasins RocksDB nouvellement générés sont mis en scène dans HDFS jusqu'à ce qu'ils soient téléchargés par les agents Flume pour garantir que le flux d'événements est enrichi avec les dernières informations.
Idéalement, nous n'aurions pas à attendre que ces ensembles de données soient tous disponibles dans HDFS avant de pouvoir les traiter. Si tel était le cas, les mises à jour des données de référence pourraient être diffusées via le pipeline Flafka pour maintenir en permanence l'état des données de référence locales.
Dans notre conception initiale, nous avions prévu d'écrire et de programmer via cron un script pour interroger HDFS afin de vérifier les nouvelles versions des magasins RocksDB, en les téléchargeant à partir de HDFS lorsqu'elles sont disponibles. Bien qu'en raison des contrôles internes et de la gouvernance des environnements de production de Santander, ce mécanisme a dû être intégré dans le même Flume Interceptor qui est utilisé pour effectuer l'enrichissement (il vérifie les mises à jour une fois par heure, donc ce n'est pas une opération coûteuse). Lorsqu'une nouvelle version du magasin est disponible, une tâche est envoyée à un thread de travail pour télécharger le nouveau magasin depuis HDFS et le charger dans RocksDB. Ce processus se déroule en arrière-plan pendant que l'intercepteur d'enrichissement continue de traiter le flux. Une fois la nouvelle version du magasin chargée dans RocksDB, l'Interceptor passe à la dernière version et le magasin expiré est supprimé. Le même mécanisme est utilisé pour amorcer les magasins RocksDB à partir d'un démarrage à froid avant que l'intercepteur ne commence à tenter d'enrichir les événements.
Les messages enrichis avec succès sont écrits dans un sujet Kafka pour être écrits de manière idempotente dans HBase à l'aide de HBaseEventSerializer.
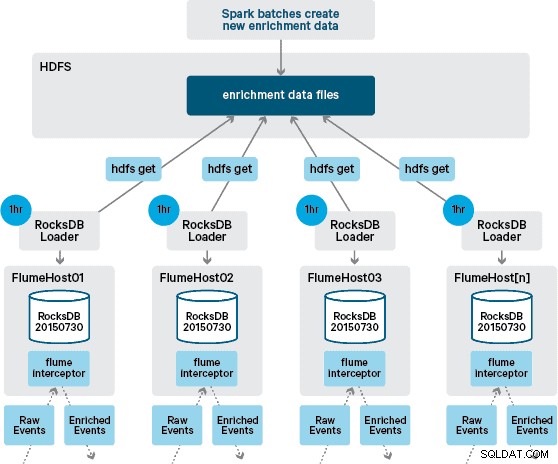
Alors que le flux d'événements est traité en continu, de nouvelles versions du magasin local ne peuvent être générées que quotidiennement. Immédiatement après qu'une nouvelle version du magasin local a été chargée par Flume, elle est considérée comme fraîche », bien qu'elle devienne de plus en plus obsolète avant la disponibilité d'une nouvelle version. Par conséquent, le nombre de «cache miss» augmente jusqu'à ce qu'une version plus récente du magasin local soit disponible. Par exemple, des informations nouvelles et mises à jour sur la marque et le commerçant peuvent être ajoutées aux données de référence, mais jusqu'à ce qu'elles soient mises à la disposition de l'enrichissement de Flume, les transactions Interceptor peuvent ne pas être enrichies ou être enrichies avec des informations obsolètes qui doivent être ultérieurement réconcilié après sa persistance dans HBase.
Pour gérer ce cas, les échecs de cache (événements qui ne parviennent pas à être enrichis) sont écrits dans un sujet Kafka « redo » à l'aide d'un Flume Selector. Le sujet redo est ensuite rejoué dans le sujet source de l'enrichissement Interceptor lorsqu'un nouveau magasin local est disponible.
Afin d'éviter les "messages empoisonnés" (événements qui échouent continuellement à l'enrichissement), nous avons décidé d'ajouter un compteur à l'en-tête d'un événement avant de l'ajouter au sujet de rétablissement. Les événements qui apparaissent à plusieurs reprises sur ce sujet sont finalement redirigés vers un sujet « critique », qui est écrit dans HDFS pour une inspection et une correction ultérieures. Cette approche est illustrée dans le premier schéma.
Conclusion
Pour résumer les principaux points à retenir de cet article :
- L'utilisation d'une chaîne de sujets Kafka pour stocker des données partagées intermédiaires dans le cadre de votre pipeline d'ingestion est un modèle efficace.
- Vous disposez de plusieurs options pour conserver et interroger des données d'état ou de référence dans votre pipeline d'ingestion NRT. Privilégiez HBase à cette fin comme modèle commun lorsque les données supplémentaires sont volumineuses, mais envisagez l'utilisation de magasins locaux intégrés (tels que RocksDB) ou de mémoire JVM lorsque l'utilisation de HBase n'est pas pratique.
- La gestion des pannes est importante. (Voir # 1 pour obtenir de l'aide à ce sujet.)
Dans un article de suivi, nous décrirons comment nous utilisons les coprocesseurs HBase pour fournir des agrégations par client des tendances d'achat historiques, et comment les transactions hors ligne sont traitées par lots à l'aide (projet Cloudera Labs) SparkOnHBase (qui a été récemment engagé dans le tronc HBase). Nous décrirons également comment la solution a été conçue pour répondre aux exigences de haute disponibilité inter-centres de données du client.
James Kinley, Ian Buss et Rob Siwicki sont architectes de solutions chez Cloudera.



